

NVIDIA通过NVLink总线串起多组GPU,发挥扩展运算性能以及可用内存容量的成效,以提高AI运算的性能与能够容纳的模型参数量。
为了要在下篇文章解释NVIDIA于Computex台北国际计算机展2025发布的NVLink Fusion,笔者需要先说明NVLink是什么东西,请各位读者忍耐一下比较艰涩的讲解。
数据中心的性能扩展基本上有2种方式,Scale Up(纵向扩展)为提高单一运算单元的性能,Scale Out(横向扩展)则为串联多组运算单元。举例来说,如果一个工厂每天可以生产100件货物,Scale Up比较像是升级至生产速度2倍的新型生产线,而Scale Out则是盖第2间厂房但使用相同生产线,2者都能达到每天生产200件货物的效果。
然而2种方案在AI运算各有限制,Scale Up受到于芯片开发高性能的技术限制,以及单一芯片的供电、散热等物理限制。Scale Out则会因多组运算单元之间的数据同步、虚耗而折损性能,且需要设置更多服务器,占用更多数据中心的楼地板面积。
NVIDIA于2021年发布的Grace CPU就导入NVLink总线,通过这种芯片对芯片互联技术(Chip-to-Chip,C2C),创建CPU(中央处理器)与GPU(绘图处理器,能够加速AI运算)之间的高速传输信道,提升整体运算性能。
2024年发布的GB200 NVL72系统,则是通过第5代NVLink互联技术将8组GB200 Superchip运算节点连接为犹如单一大型GPU的运算单元,其中总共包括36组Grace CPU与72组B200 GPU。若是搭配NVLink Switch机架级交换机芯片,最高能将576组B200 GPU组成无阻塞运算网状架构的完全互联GPU,发挥类似Scale Up的性能扩展效果。
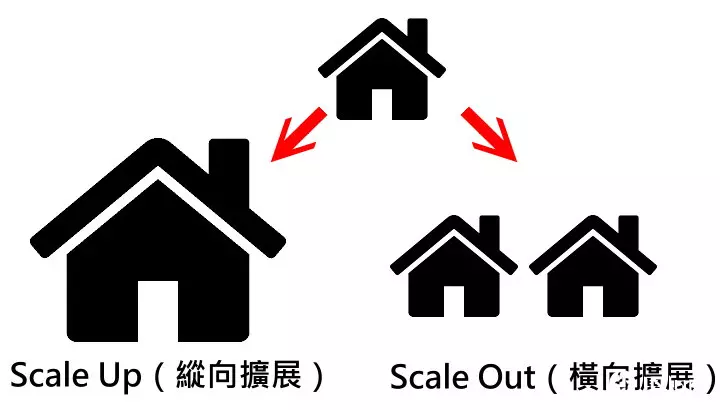 以工厂为例,Scale Up(纵向扩展)的概念像是提升工厂生产线的效率,而Scale Out(横向扩展)则为扩建新厂,2者都能提生产能。(图中房屋素材取自Flaticon,采用创用CC3.0姓名标示授权)。
以工厂为例,Scale Up(纵向扩展)的概念像是提升工厂生产线的效率,而Scale Out(横向扩展)则为扩建新厂,2者都能提生产能。(图中房屋素材取自Flaticon,采用创用CC3.0姓名标示授权)。
 NVIDIA推出的Grace Hopper Superchip搭载Grace CPU与Hopper GPU,2者通过NVLink互联。
NVIDIA推出的Grace Hopper Superchip搭载Grace CPU与Hopper GPU,2者通过NVLink互联。
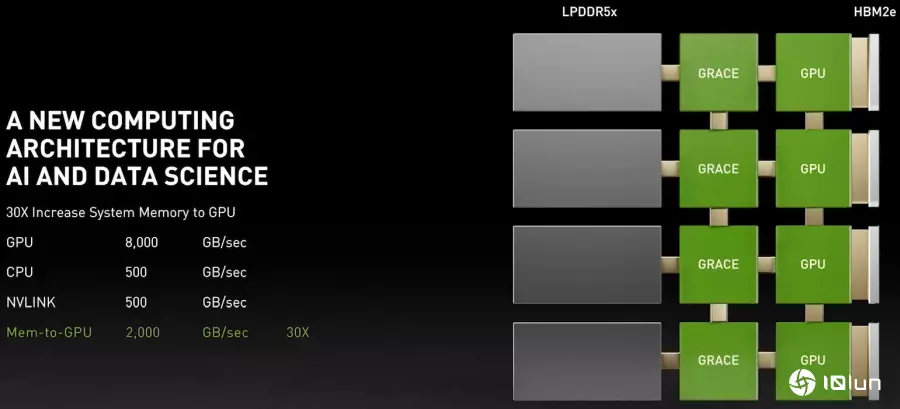 Grace处理器也通过NVLink连接主内存与内置于GPU之绘图内存,高达2 TB/s的带宽可带来显著的AI性能增长。
Grace处理器也通过NVLink连接主内存与内置于GPU之绘图内存,高达2 TB/s的带宽可带来显著的AI性能增长。
另一方面,NVDIA于2019年收购Mellanox后,也将InfiniBand网络互联技术应用于AI运算服务器的Scale Out,串起多组由NVLink组成的运算节点,进一步提升整体运算单元的规模。根据NVIDIA官方网站说明,InfiniBand能够连接数十万组GB200 Superchips。
(笔者注:原文如下,Multiple racks can be connected with NVIDIA Quantum InfiniBand to scale up to hundreds of thousands of GB200 Superchips.)
值得注意的是,无论在AI训练或AI推论等运算过程中,除了运算性能之外,内存容量是相当重要的规格指标,若位于GPU或是由CPU管辖的内存容量不足,可能就会造成运算性能骤降或是甚至无法完成运算的状况。
但是在单一GPU上搭载的内存容量受到成本考量、散热、供电,以及GPU本身性能与内存匹配效率(若GPU性能不够强,搭载过多内存对性能没有帮助)等因素的综合考量。举例来说NVIDAI的GB200 Superchip最多搭载480 GB LPDDR5X以及384 GB HBM3e内存,而AMD Instinct MI350系列则搭载288 GB HBM3e内存。
若需要训练或使用规模更大、参数量更多的AI模型,势必须通过各种Scale Up与Scale Out技术扩展运算单元的数量,进而访问更大容量的内存。
 黄仁勋在Computex台北国际计算机展2025发布的Grace Blackwell Ultra Superchip同样可以通过NVLink相互联接组成“超大GPU”。
黄仁勋在Computex台北国际计算机展2025发布的Grace Blackwell Ultra Superchip同样可以通过NVLink相互联接组成“超大GPU”。
 简单地说在NVIDIA的生态系统中,NVLink芯片对芯片互联技术是用来将多组GPU组合成单一运算单元的Scale Up,而InfiniBand或以太网络等网络互联技术则为串联多组单元的Scale Out。
简单地说在NVIDIA的生态系统中,NVLink芯片对芯片互联技术是用来将多组GPU组合成单一运算单元的Scale Up,而InfiniBand或以太网络等网络互联技术则为串联多组单元的Scale Out。
NVIDIA通过NVLink、InfiniBand与以太网络等互联方式达到Scale Up与Scale Out等扩展功效,提高整体运算性能并支持量体更大的AI模型。笔者将在下篇文章说明NVLink Fusion。








