

近来不少人担心,随着网络上充斥越来越多由AI产生的内容,像Google AIO这类集成型搜索服务,是否也会开始引用这些“AI写给AI看”的资讯。由于AI生成内容经常出现凭空捏造、难以查证的问题,若AI模型不断学习自身产出,恐将陷入“AI学AI”的恶性循环。
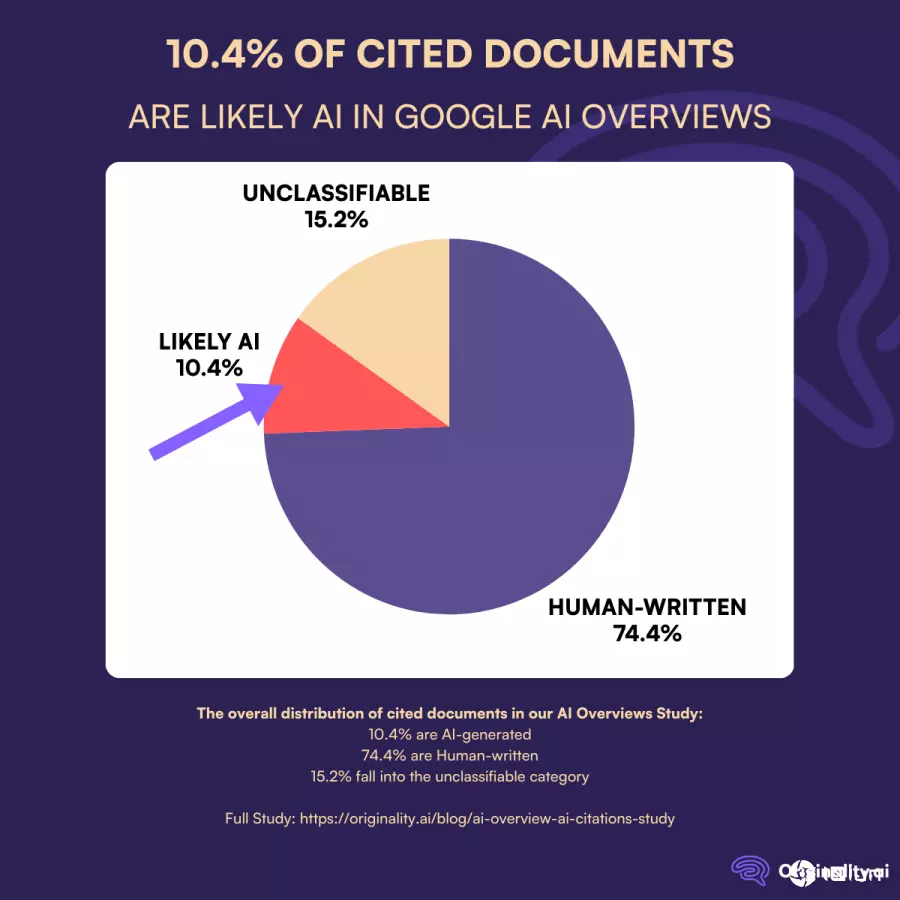
AI内容侦测公司Originality.ai最新公布的研究指出,他们针对2.9万个与个人健康、安全、财务状况及幸福感相关的高风险(YMYL)关键字进行随机抽样,分析Google搜索顶端AIO所引用的网页,以及该关键字下前100名自然搜索结果。结果显示,有10.4%的AIO引用来源很可能为AI生成内容。
早在2023年,英国与加拿大研究人员就提出“递归诅咒”(The Curse of Recursion)这个概念,警告若AI模型频繁吸收AI生成数据,将导致模型出现“不可逆缺陷”,甚至造成所谓的“模型崩溃”。Originality.ai也认为,AIO虽然本身不是训练AI模型的数据源,但它若经常推荐AI文章,反而会让这些内容获得更多曝光与公信力,间接提高被纳入训练数据的机率。
对于这项研究,Google发言人表达质疑,批评Originality.ai“过度依赖单一数据与不够准确的技术”,并强调目前市面上的AI侦测工具仍不够成熟、容易误判。此外,Google也表示,AIO引用的内容会随时根据相关性、实用性与时效性进行调整。
尽管如此,Originality.ai强调,他们的工具在多项测试中表现不俗,准确率相对较高。研究同时指出,目前AIO引用内容中,仍有74.4%属于人类原创;有15.2%的结果因文本太短、连接失效或是指向影音、PDF等非文本格式,无法进行识别。
另一项值得注意的数据是,有52%的AIO引用内容并不在Google自然搜索前100名结果中,其中有12.8%也被标记为AI生成内容。这样的结果进一步凸显:即使AI搜索工具的目的是提升搜索体验,但若无法识别来源品质,恐怕会成为扩大AI“自我学习”的助力。







