
今年的I/O大会,是Google生成式AI(GenAI)技术和应用大爆发的一次。除了端出各种令人惊艳的消费端GenAI成果,他们还披露一系列用GenAI模型加速企业开发的工具,尤其,这些工具是Google内部实例经验的延伸,发展为对外服务、瞄准4大场景。
开发场景优化1:快速生成互动式UI
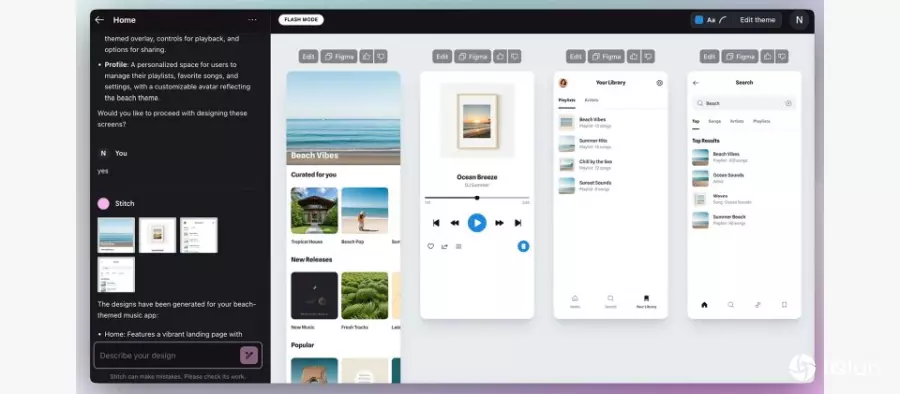
他们首先披露,生成式AI模型加速UI设计的工具。
“Gemini 2.5 Flash模型又快又划算,我们用它打造了很多原型!”Google Gemini实验室副总监Josh Woodward在大会上如此开场。Gemini 2.5是Google开发的新一代生成式AI模型,今年3月发布Pro版本、4月披露Flash版本,就成为Google内部开发的加速工具。
Google将生成式AI模型落地的成功经验,进一步扩大到自家产品,以Gemini 2.5系列模型为核心,融合程序开发和设计,推出一款名为Stitch的实验性UI生成工具,用户用自然语言提示(Prompt),就能在1分钟左右得到UI原型和程序代码。
这个UI“不是静态的屏幕截屏,而是可以互动的界面,”Josh Woodward强调。跳出第一版UI后,用户还能继续在对话栏,用自然语言提示修改UI原型,另也能手动调整区块颜色、亮暗模式等。在这过程中,Gemini 2.5 Flash和Pro版本模型会互动工作,来根据提示产生、修正UI原型。
要是用户对生成的UI满意,就能复制程序代码,贴到自己喜好的IDE环境或Figma工具继续编辑,或与团队协作。
开发场景优化2:快速生成Web App
除了加速UI设计,Google也用生成式AI产出网页App原型。
进一步来说,Google Cloud原本就有套一站式生成式AI开发工具Google AI Studio,它串联自家Gemini系列模型和其他模型API,用户在网页界面输入提示,就能生成各种内容,如程序代码、图片、影音等。
这次,Google DeepMind集团产品经理Logan Kilpatrick披露新突破,他们把最新、最擅远程序代码处理的Gemini 2.5 Pro模型,集成到Google AI Studio原生编辑器,加上自家GenAI SDK优化,更容易根据文本、图片或视频提示,来生成网页应用原型,缩短开发时间。
Logan Kilpatrick现场输入提示,要打造一套冒险游戏应用程序,系统马上调度Gemini和Imagen模型,先生成游戏规格,再产生程序代码、自我修复错误,并在几分钟后,产出错含画面的应用程序原型。
之后,开发者可继续通过聊天界面,来调整、查看不同的原型版本,也能回溯到先前的检查点、还原修改等。开发者甚至能一键将新建的网页应用,部署到Cloud Run上。
开发场景优化3:大规模开发自动化
从用生成式AI模型生成UI、App,Google还用生成式AI来加强程序开发本身,在今年大会中披露程序开发代理Jules公测版。
这个领域并非Google独步,不少公有云大厂和程序开发企业都推出专属GenAI辅助开发工具,而Google这款Jules,是一套可在背景作业的异步代理型AI开发助理,它以Gemini 2.5 Pro驱动,具备集成GitHub项目、自动完成一系列开发工作的能力。
Jules会将开发者的程序代码库复制到Google云计算VM,来写测试、构建新功能、修复错误、升级相依组件版本、提供语音版的变更记录等,开发者一边工作,Jules就能在后台执行作业,完成后会提供说明。
特别的是,Jules可同时执行多任务,在VM中同时处理多个请求,适合大型、多文件的变更。
开发场景优化4:AI代理融入开发环境
同样是改善开发体验,Google还将生成式AI带入自家开发环境Colab,在今年大会宣布升级为AI优先的Colab。因为,他们用Gemini 2.5 Flash驱动的代理,来提供一系列优化功能,可在整个Notebook环境执行。
这些功能主要几种,比如常见的程序代码生成和转换改写、查询Python函数库和请求使用范例、直接在Notebook中提出错误修复建议等。
另一类功能是结合新一代数据科学代理(DSA)的能力。今年3月,Google推出DSA,协助用户探索数据、深入分析和找出洞察,而这次,Google升级DSA,集成至Colab的AI体验中,用户可要求Colab审查已上传和现有文件、进行深度分析,还能触发完整的分析工作流程,包括先自主生成分析计划、执行必要的程序代码、推理结果并呈现其洞察。
此外,融合升级版DSA的Colab,还能给予互动式反馈,在计划执行过程中提供反馈,好来决定是否重新规划或优化流程,确保分析结果贴近用户的研究目标。
强化AI代理App开发工具链
不只将自己善用GenAI加速开发的经验产品化,变成生成UI、网页App工具,Google也用生成式AI,来优化AI代理App的开发。
比如Logan Kilpatrick宣布,Google GenAI SDK开始支持模型上下文协议(MCP),简化开发者打造AI代理App的难度,让App背后的模型更容易串联开源工具、给出更精准的回答。
再来,为了让AI代理App更自主完成任务,Google除了改善模型的函数调用、搜索功能,还进一步推出新实验性工具URL Context,用户只要输入网页连接,模型就能查阅该网页资讯,来确保生成的答案更即时精准。该工具目前一次可支持20个连接。
同时,Google也优化模型本身,来让AI代理App的体验更好。
首先,Google在其即时语音Live API中,新添Gemini 2.5 Flash原生语音功能(Native Audio)预览版,让AI更会听、更会说,不只生成的语音更自然、模型能即时调用工具、支持24种语言,用户还能控制模型的声音、语调、整体风格。而且,模型能更好地识别说话者和背景对话,进而判断何时该回应,让开发者能打造更自然的对话式AI体验。
此外,Google也将自家研发的多模态模型,集成至App开发工具,包括Imagen、Veo、Gemini等,范围涵盖图像、视频、音频和语音生成,开发者可打造更多功能的App。
推新一代开放模型,供微调加速落地
不只提供生成式AI驱动的现成服务,Google也端出一系列新的开放模型,供开发者自行训练或微调成符合需求的工具,来执行特定任务,脱机也可以。
比如,今年大会新推出Gemma 3n预览版,只需2GB内存,就能在移动设备端执行任务。它还有几个实务性优点,如多模态理解能力,可以理解并处理文本、图像、语音和视频内容,也支持多模态互动输入,另还内置可自动切换的子模型,例如从4B模移动态产生2B子模型,来应对不同设备和延迟需求。甚至,模型的日语、德语、韩语、西班牙语和法语翻译能力也更强了。
Google给出Gemma 3n可行的应用场景,比如可分析用户环境(音频、视觉)的即时互动体验、深层理解多模态(文本、图片、音频和视频等)的脱机应用,又或是即时语音转录、翻译和语音互动等应用。
还有多种专属开放模型和开发社交媒体
除了Gemma 3n,Google也在Gemma 3模型架构基础上,亮相几款专用模型。首先是医疗领域专属的MedGemma,它指一系列以Gemma 3为基础、以医疗看护数据打造而成的模型,包括4B参数(即40亿)的多模态模型,以及27B参数的文本模型。MedGemma可以进行医学形象分类、解读形象和生成报告,还能进行临床推论、辅助临床决策和摘要重点,比如协助医生判读X光片、病理形象并写报告。开发者可以微调模型,在云计算或本地端部署,来执行特定任务。
另一款专属模型是手语识别模型SignGemma,专为聋哑和听障社交媒体打造,可作为即时翻译工具,能将美国手语转换为英文。Google点出,SignGemma属于轻量化设计,可在资源有限的设备上执行,潜在的应用场景有即时翻译应用、将手语转换为文本或语音,可用于一般场合或是教育、医疗等场景。
SignGemma目前仍于测试阶段,预计今年底正式发布,未来预计扩展至更多手语和语言。
这两款专属模型,还只是众多开发者可用的其中2种。早在今年3月,Google就专门为Gemma开发者,成立了专属社交媒体Gemmaverse。在这里,开发者可以交流创意、查看各种Gemma衍生应用。Google披露,自Gemma系列模型发布1年多以来,相关模型下载量已超过1.5亿次,更累积超过7万个Gemma变形模型,这也是Google为其成立社交媒体的原因,让开发者吸取更多实例、开发可落地的应用。







