
在半导体产业中,芯片尺寸与良率之间的关系长久以来一直被视为难以突破的限制。传统观念认为,芯片越大,良率越低。然而,Cerebras公司却成功挑战了这个传统思维。
Cerebras设计并商业化了一款比目前最大运算芯片还要大50倍的芯片,却依然能够达到相当的良率,这项成就引发了业界的好奇与关注。Cerebras如何克服芯片尺寸带来的巨大挑战,在芯片级处理器中实现可用的良率,成为众人急于理解的焦点:Cerebras是如何在芯片级处理器中实现可用的良率的?
答案在于重新思考芯片尺寸与容错率之间的关系。本文将提供一个详细的、逐项比较的分析,探讨Cerebras Wafer Scale Engine与一个H100大小芯片(同样使用5nm制程)的制造良率。通过查看缺陷率、核心大小及容错率的相互作用, Cerebras将展示如何在芯片级集成中实现与限制在光罩范围内的GPU相等甚至更高的良率。
如同任何制造流程,计算机芯片不可避免地会有缺陷。较大的芯片更容易遭遇缺陷,因此随着芯片面积增大,良率会指数级下降。尽管较大的芯片通常运行速度更快,早期的微处理器为了维持可接受的制造良率与利润,通常选择适中的尺寸。
然而,这一情况在2000年代初期开始改变。当晶体管数量超过一亿后,设计师开始在芯片中加入多个独立核心。由于这些核心是独立且相同的,芯片设计师引入了核心级容错机制,让即便某个核心存在缺陷,其他核心仍能正常运行。例如,2006年Intel推出了Intel Core Duo(双核心处理器)。如果其中一个核心出现缺陷,该产品仍可作为Intel Core Solo(单核心处理器)销售。Nvidia、AMD等公司随后也采用了这种核心级冗余设计。
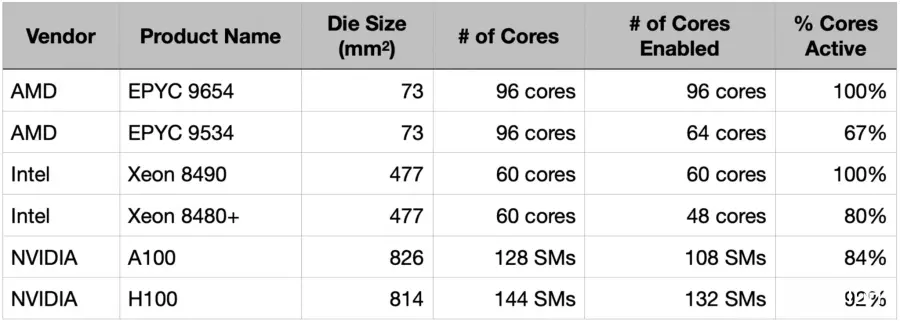
如今,高性能处理器广泛使用容错设计,并且售卖部分核心被禁用的芯片已成为常态。AMD和Intel的处理器通常推出一个全部核心可用的旗舰版本,并搭配部分核心被禁用的低端版本。同样,Nvidia的数据中心GPU体积远大于CPU芯片,因此即使是旗舰型号也会禁用部分核心。
以Nvidia H100为例,这是一款面积达814mm² 的大型GPU。传统上这种芯片很难以经济的方式完成高良率。然而,由于其核心(SM,流式多处理器)具备容错能力,制造缺陷不会让整个产品报废。该芯片实际上有144个SM,但商业化产品仅激活132个SM,这意味着即便有多达12个SM出现缺陷,该产品仍可作为旗舰型号销售。
传统上,芯片尺寸直接影响芯片良率。但在现代,良率是芯片尺寸与容错率的函数。过去被认为无法经济商业化的800mm² 芯片,通过容错设计,现已成为主流产品。
容错率的程度可由缺陷发生时损失的芯片面积来衡量。对于多核心芯片而言,核心越小,容错率越高。如果单个核心足够小,就有可能制造非常大的芯片。

在Cerebras,决定构建芯片级芯片之前, Cerebras首先设计了一个非常小的核心。Wafer Scale Engine 3中的每个AI核心约为0.05mm²,仅为H100 SM核心大小的约1%。这两种核心设计均具备容错能力,这意味着一个WSE核心的缺陷仅会损失0.05mm²,而H100则会损失约6mm²。从理论上来看,Cerebras Wafer Scale Engine的容错率比GPU高约100倍,考虑的是缺陷对硅面积的影响。
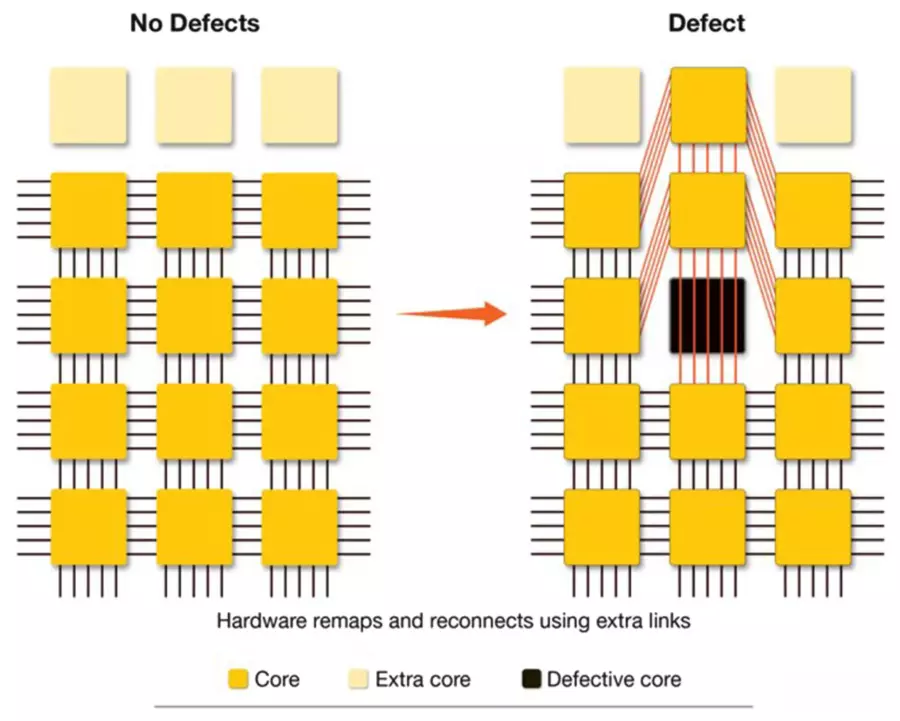
但仅仅拥有小核心还不够。 Cerebras还开发了一种精密的路由架构,能够动态重新配置核心之间的连接。当侦测到缺陷时,系统可通过冗余通信路径自动绕过缺陷核心,并利用邻近核心保持芯片的整体运算能力。
该路由系统与小量备用核心协同工作,能够替换受缺陷影响的核心。与以往需要大规模冗余的方式不同, Cerebras的架构通过智能路由实现了以最少备用核心完成高良率。
让Cerebras比较在TSMC 5nm、300mm芯片上的传统GPU和芯片级芯片的良率:
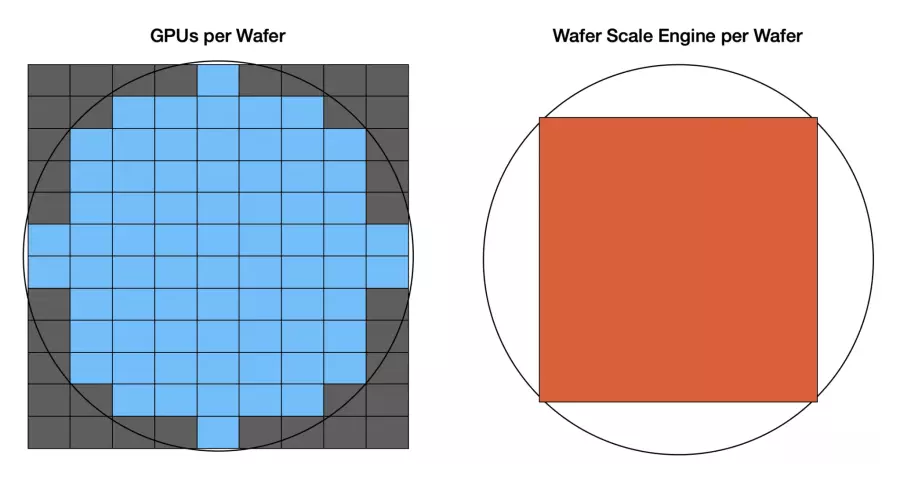
左侧是一个类似H100的GPU:面积为814mm²,包含144个容错核心,单个300mm芯片可产生72个完整芯片。右侧是Cerebras Wafer Scale Engine 3,其为一个46,225mm² 的大型正方形芯片,拥有970,000个容错核心。一个芯片只能产出一片芯片。
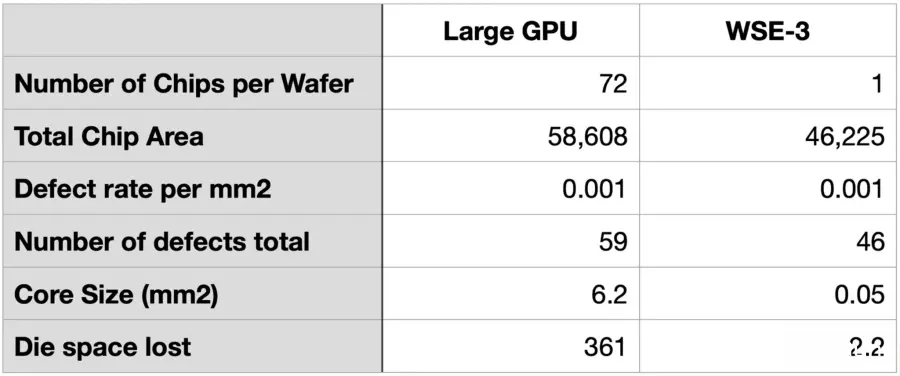
在当前的TSMC 5nm节点下,TSMC制程的缺陷密度约为每mm² 0.001。72个GPU芯片的总面积为58,608mm²,按此缺陷密度运算,这些面积中将出现59个缺陷。假设每个缺陷都影响不同核心,则每个核心面积为6.2mm²,总计会损失361mm² 的芯片面积。
对于Cerebras来说,有效芯片面积稍小,为46,225mm²,按相同的缺陷密度,将会出现46个缺陷。每个核心仅为0.05mm²,因此总损失面积仅为2.2mm²。
总体来说,在相同制程和缺陷率下,GPU的损失硅面积比Wafer Scale Engine多164倍。
尽管上述运算简化了部分细节,但其基本规律依旧成立:核心越小,容错率越高。
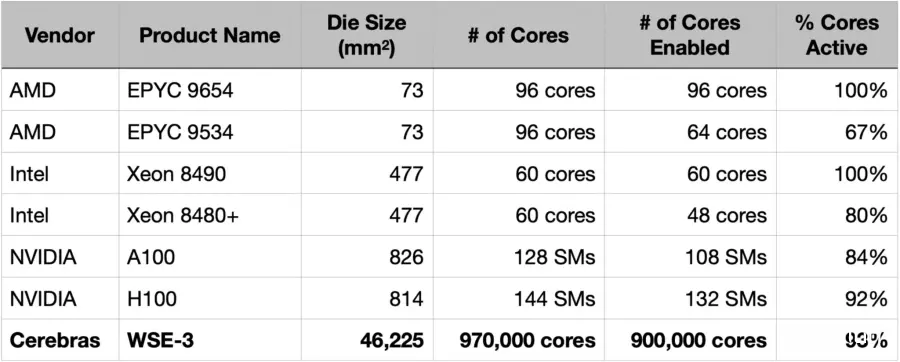
让Cerebras回顾比较表,并将Cerebras Wafer Scale Engine加入其中。与Nvidia的数据中心GPU一样,WSE-3采用了容错设计,并禁用了部分核心以管理良率。由于Cerebras的核心非常小,总核心数量高达970,000个,当前商业化产品中激活900,000个核心,提供了极为精细的容错能力。
尽管Cerebras建造了世界上最大的芯片, Cerebras的硅面积使用率达到93%,高于当今领先的GPU。
Cerebras通过设计小型容错核心和容错片上结构,解决了芯片级制造挑战。尽管总芯片面积比传统GPU增加了约50倍,但Cerebras将单一核心大小缩小了约100倍。结果,缺陷对WSE的损害远低于传统多核心处理器。第三代WSE引擎达到93%的硅使用率,这证明芯片级运算不仅是可能的,更能在商业规模下实现。








