
今年3月,鸿海研究院披露了自家大型语言模型FoxBrain,后来在Nvidia GTC大会中进一步说明技术亮点,包括在预训练阶段用LLM来过滤原始数据并分类、结合LLM和COSTAR框架来产出品质更好的训练数据,以及在后训练阶段用LLM生成更多训练数据。甚至,他们也用LLM生成正确的推理过程,来强化FoxBrain推理能力,同时也用AI反馈强化学习(RLAIF)方法,来以AI为裁判,判断FoxBrain产出的答案品质,用比人工更快的方式教导模型对齐人类价值观。
亮点1:用LLM过滤原始数据
这个FoxBrain是以Llama 3.1 70B模型为基础,以120张H100 GPU、花4周训练而成,不只繁中能力超越Llama-3-Taiwan-70B,还具备良好的数学和逻辑推理能力,可执行数据分析、决策辅助、文书协作和程序代码生成等任务。
FoxBrain的技术亮点之一,是用LLM来过滤原始数据和分类。鸿海研究院技术负责人Van Nhiem Tran在Nvidia GTC大会中指出,FoxBrain模型训练可分为连续预训练(Continual pretraining)和后训练(Post-training)阶段,在预训练阶段,模型需要庞大训练数据,因此团队从开源数据集、外部数据(如arXiv、PubMed、新闻媒体等)和内部数据来收集训练数据,同时根据期望模型具备的领域知识,来决定数据范围,比如中英文数学和程序能力、台湾和世界金融知识、鸿海知识、高端推理能力等。
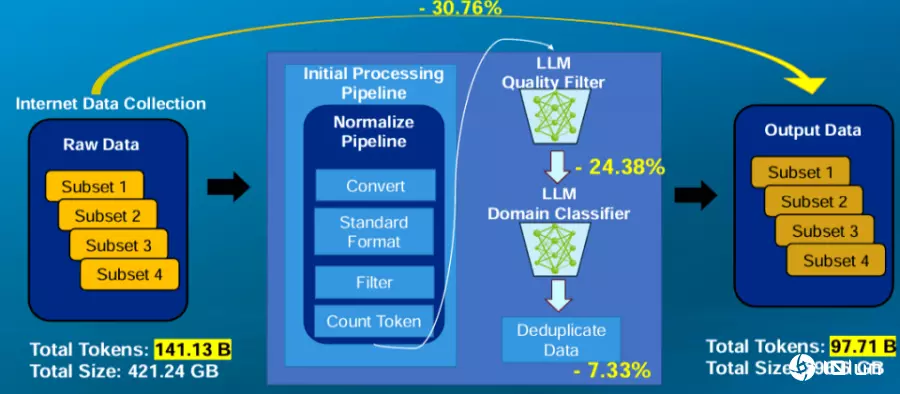
收集这些数据后,很重要的一步是数据过滤,筛选出可用的训练数据并分类。在这个阶段,鸿海将收集到的141.13B Token原始数据(即1,413亿个Token),先经过一系列范式初始处理,再通过LLM进行品质过滤、筛掉一部分原始数据,再由另一个LLM进行领域分类,筛除7.33%的重复性数据,最后产出不同子集的训练数据集,共97.71B Token。(如下图)
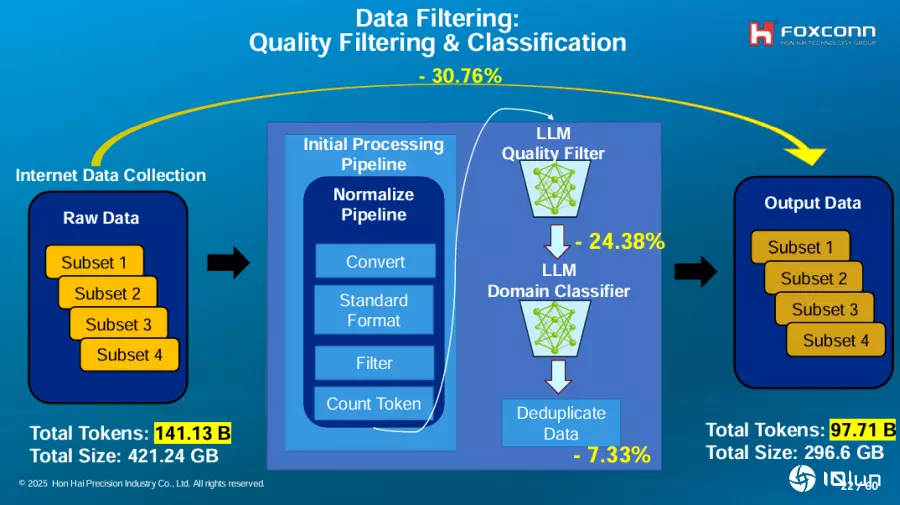
但如何用LLM过滤数据?Van Nhiem Tran解释,他们设计了数据品质评分标准与一套评分用的提示指令,当LLM接收一笔数据后,会根据这套提示对原始数据评分。一旦超过规定分数,这笔数据就会被保留,再由另一个LLM归类这笔数据,比如科学、财经等。有别于常见的重复性过滤,这个方法更能理解数据的语义表现,更能筛选出高品质数据。(如下图)

亮点2:用LLM强化训练数据品质
另一个技术亮点是用LLM来进行数据增强。这一步是在数据过滤和分类后,通过LLM来改写这些数据,让数据变得更有结构、文意更清楚易懂,且包含更多观点。
要改写数据,还需要一套统一的标准。于是,团队先用COSTAR框架来设计提示,让LLM根据提示要求,改写数据(补充说明:COSTAR是常见的提示词写作框架,包含背景资讯Context、具体目标Objective、写作风格Style、语气Tone、受众Audience和回复格式Response,但鸿海团队将其用来设计改写提示)。比如,产生一份关于计算机和电子产品的网页内容(对应C)、给高中生阅读(对应O)且简单易懂的版本(对应S)。(如下图)

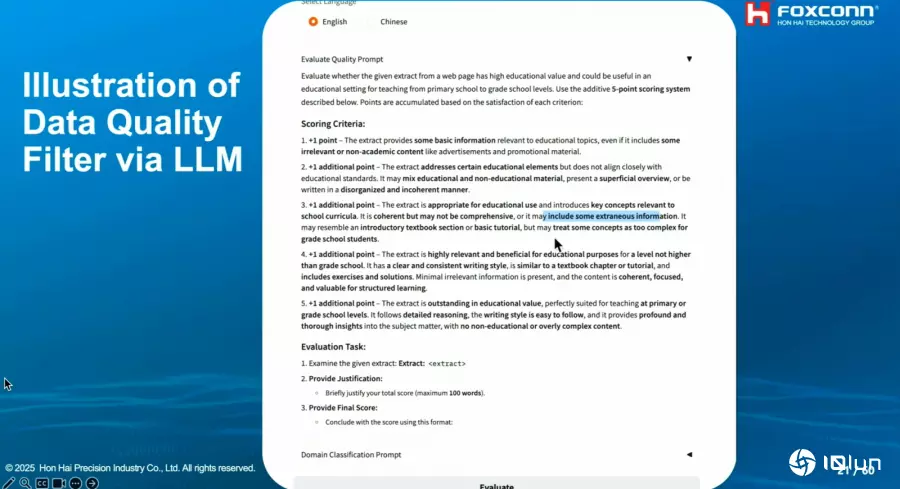
有了提示标准,团队再来要找出各类别最适合改写的LLM,而非用一套LLM改写所有类别的数据。因此,他们根据数据过滤和分类后产生的类别,分别找出各类别代表性数据,再用几个小型LLM来改写这些数据。接着,他们用一套LLM作为评审,来评估这些改写后的数据分数,进而找出哪个LLM最适合改写哪个类别。(如下图)

他们评估小型LLM表现的指标有几个,比如文意清晰度、初衷保留度、深度、描述性、观点多样性等等。他们评估的模型有Qwen 2.0、Llama 3.0与3.1、Gemma 2和DeepSeek-V2等,也成功找出各类别最适合用来改写/增强的模型,比如Gemma 2最适合用来强化科学类数据。(如下图)
有了这些资讯,他们就构建一套工作流程,来根据筛选后的数据类别,以最擅长该类别的LLM来改写,进而提高训练数据品质。
亮点3:用LLM生成更多训练数据
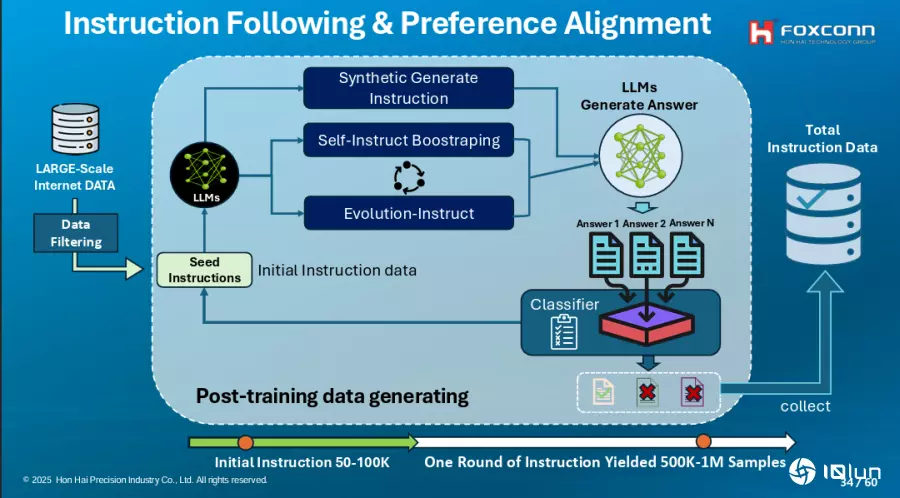
上述的数据过滤分类和数据增强,都是为预训练数据的准备。预训练之后是后训练阶段,有别于预训练需要大量数据,后训练聚焦模型特定领域能力,通过相对少量的数据来微调。
在这个阶段,团队也用不少AI辅助方法,其一是用LLM生成数据。他们先用模型生成问题,再用其他LLM来回答问题,产出各自的答案。这时,还会有套LLM根据规则来评分这些答案并分类,最后,这些问题-答案组就会纳入后训练数据集。(如下图)
亮点4:用AI辅助模型训练
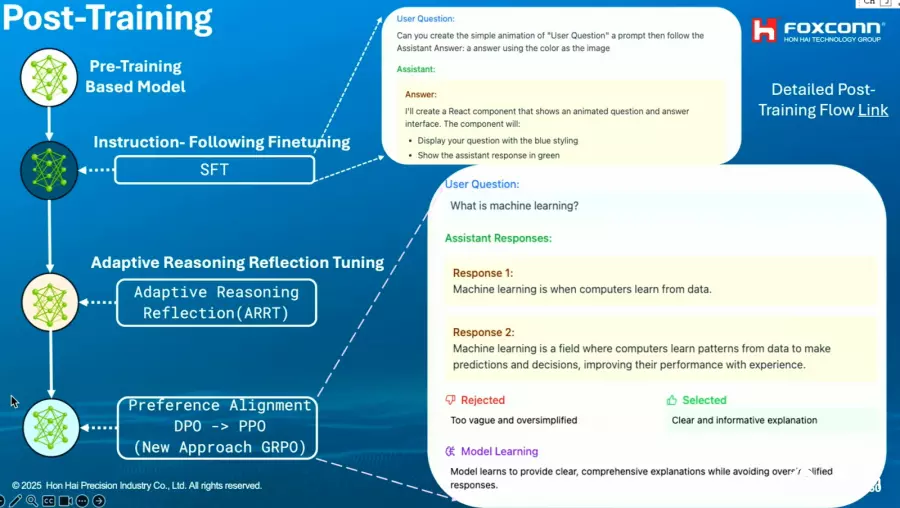
同样是在后训练阶段,团队还有些特别的技术,来微调模型。
其中一种方法是Adaptive Reasoning Reflection(ARRT),来让模型学习自主推理。鸿海研究所AI所长栗永徽说明,这个方法需要团队准备许多问题及相对应的答案,而且,这些答案不只有最后的解答,还有中间的推理过程。为节省推理过程数据收集的时间,鸿海团队用AI大模型,来针对各种问题,产出正确的推理过程。(如下图)

同时,为确保模型不会一直无限制推理、消耗太多Token,鸿海团队还设计一种方法,来让模型学习,如何根据题目难易度来自动决定推理所需的Token量,以此作为限制条件,也就是Adaptive的意思。
栗永徽点出,经ARRT训练的FoxBrain模型变得聪明许多,与DeepSeek相比,有些简单问题, DeepSeek可能会一直思考才给答案,但FoxBrain对难的问题会多思考,对简单的问题则思考快一些,在适当的时间内产出正确答案。
除了ARRT,团队还用了AI反馈的强化学习方法(RLAIF)来进行后训练,也就是以AI作为裁判,来在模型产出回答后,判断回答好不好,进而教导模型对齐人类偏好的答案,大幅提高效率。(如下图)
最后,为了让FoxBrain更贴近实用场景、能在计算资源有限的设备上执行,鸿海团队还使用压缩技术,比如剪枝、参数或权重稀疏(Sparsity)、量化等方法,来减少模型所需的内存和计算资源,兼顾速度和模型表现。
以上图片来源/鸿海研究院








