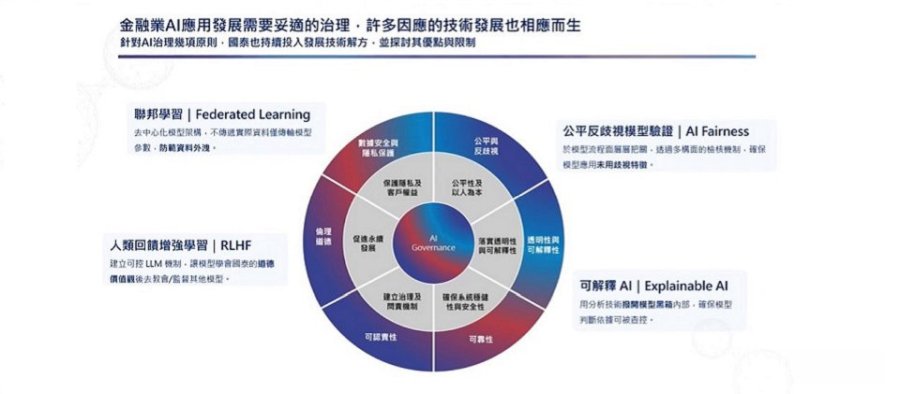
国泰金控今日(9/20)在自家技术年会上,首度公开了实现AI治理原则所投入的4大技术研发进展,包括运用SHAP算法来解释AI模型、自建公平反歧视模型验证方法、导入联邦学习,以及在模型加入人类反馈增强学习(RLHF)方法的最新成果。
透明性和可解释性是国泰金控AI治理中的重要原则。过去,传统模型中的特征数量较少,权重可被观察,然而,现在常用的神经网络模型参数量大,数据科学家难以观察权重变化,运算过程犹如黑盒子,用户无法得知模型产出答案背后的依据。
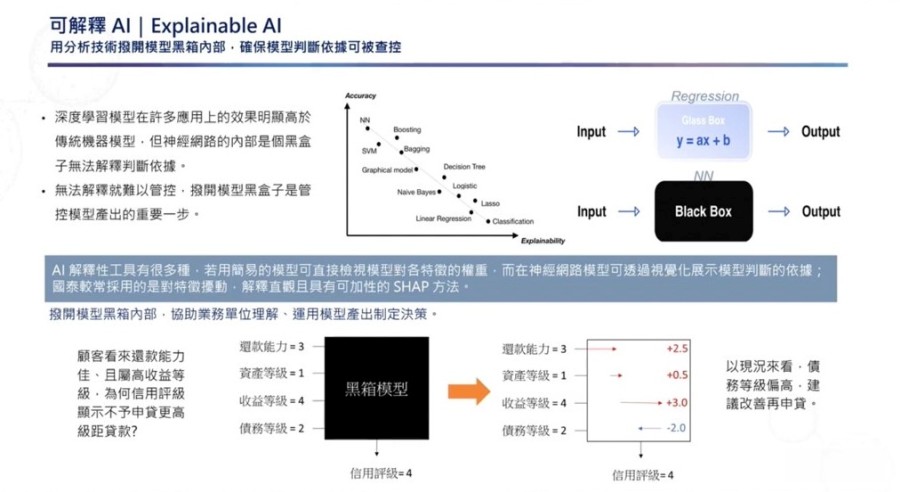
为解决这个痛点,国泰金控数据科技发展部协理刘浩翔在自家技术年会指出,在他们采用的可解释性方法中,SHAP算法是最常用的一种,可用来可视化模型中的判断依据。简单来说,SHAP可根据模型的输出值(Output),来回推、解释模型特征与产出答案的关系,进一步让业务单位了解AI算出该答案的原因。
他举例,原先业务仅能看到顾客还款能力好,且收益等级高,无法得知信用评级低的原因,但经过SHAP反推结果,可以得知顾客在债务等级相较过去高了两个等级,是信用评级低的主要原因。这个做法可让模型运算更透明,协助业务单位制定决策。
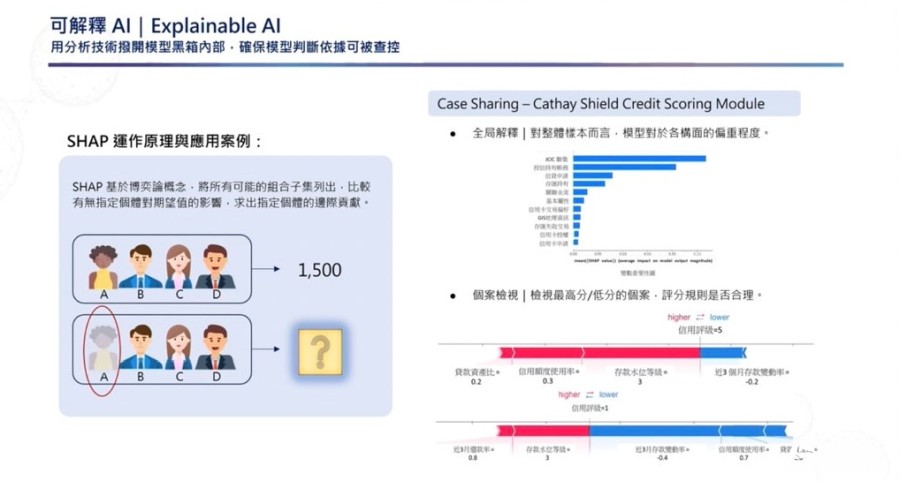
另一个例子是,由于SHAP算法针对结果逆推运算过程,因此可借由反复抽换单一实例,来测试实例对评分造成的影响,也就是计算单一实例对整体模型的边际贡献值。对整体样本而言,SHAP可以帮助用户了解模型对于各构面的偏重程度,并以程度高低进行排列。而对个案而言,用户可以借SHAP查看最高分或最低分的个案,并进一步观看评分规则是否合理。
另一方面,公平与反歧视也是国泰金控AI治理的一大原则。“有些时候真的不是模型越准越好,”刘浩翔解释,若金融业使用的AI模型以带有歧视或偏见的特征对客户进行评分,可能加剧社会的不公平性。因此,国泰金控创建一套公平反歧视验证检核机制,来确保模型未使用含有歧视意味的特征。这个方法可分为2步骤,一是在训练模型前,先盘点数据、确保模型不使用具歧视的特征,以进行事前约束。再来,模型训练完后,再以统计检验群体间预测的分布是否有异,来进一步移除带有歧视性的特征。这是国泰金控用来保障模型公平、反歧视的2阶段做法。
刘浩翔表示,虽然舍弃歧视特征会影响模型表现,但在特征数量足够的情况下,还是有可能以其他特征组合补偿降低的表现分数。国泰金控团队实验发现,在移除某歧视特征后,随着特征数量越多,模型表现受到的影响会逐渐变小。
但是,若移除矢量空间较为独立的歧视特征,模型受到的影响仍会存在。“这个情况相对稀少,”刘浩翔表示,大多数的情况下,移除歧视性特征后,仍可以被大量的特征数量弥补。他认为,运用公平跟反歧视的ai是金融业不得不承受的趋势,也因此,“不使用带有歧视性或偏见的特征,绝对是我们必须做出的取舍。”刘浩翔说道。
在数据安全与隐私保护上,国泰金控还有另一个做法。他们采用联邦学习(Federated Learning)来实践,由于联邦学习主打去中心化架构,有别于传统集中式机器学习方法,企业不需要将数据共同集中至某处才能训练模型,而是在各端点(企业)持有一套模型,用各自的数据训练模型、再将训练好的模型权重集结起来优化,之后再下放到各端点,进行下一轮模型训练,反复这个过程直到模型收敛为止,就能训练好模型。
这么做,不仅能防范数据外泄,也能确保模型表现。因此,刘浩翔表示,这项技术有许多适合金融业运用的特性。
例如,国泰金控研究发现,随着子公司越多,模型的成效越高,且即便发起端拥有的特征数较少,模型仍有一定表现。此外,若子公司分散的特征越多,对模型也并未有显著影响。
为了确保AI具备伦理道德,国泰金控以人类反馈增强学习方法,来让AI学会公司的价值观。刘浩翔解释,国泰在LLM模型后加上以人类偏好所训练的奖励模型,借此让模型理解人类喜欢和不喜欢的回应。例如,当模型的回应不是人类喜欢的答案,就会将奖励模型回送到LLM里进行强化学习,慢慢教会模型,给予符合人类道德和价值观的回应。
最后,国泰也表示,经过研究显示,模型中投入越多的参数量,模型表现越好,且在仅针对特定领域进行回应的LLM中,即便只运用小的参数量进行训练,效果也接近采用大参数量的模型。此外,进行Fine tune及加入RLHF都可以让LLM模型效果更好,且加入RLHF机制的模型得到的分数高于进行Fine tune的模型表现。








