AWS在机器学习服务Amazon SageMaker添加回应流媒体(Response Streaming)新功能,用户现在可以将模型推论结果流媒体传输至客户端,在回应生成时立即开始流媒体传输回应,不必等待回应完全生成,而这将可加速生成式人工智能应用程序收到第一个字节的时间。
过去用户发送查询,需要等待回应完全生成完毕,才能够收到答案,是以批次作业的方式进行,但是这可能会需要数秒或是更长的时间,官方提到,这样的形式降低了应用程序的性能。通过应用回应流媒体功能,应用程序可以更快地产生回应,在用户看到初始回应时,人工智能可以继续在后台完成处理其解答,聊天机器可以更迅速发送生成结果,如此便能够创建无缝地对话流程,让最终用户获得流畅的对话体验。
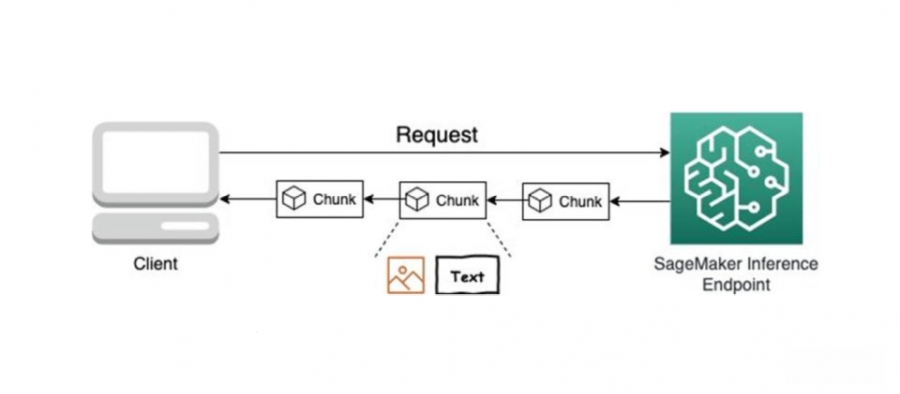
要从SageMaker截取流媒体回应,用户需要使用新的InvokeEndpointWithResponseStream API,应用程序将可以更快地收到第一个回应字节,用户会明显有感觉延迟降低,AWS提到,在人工智能应用程序中,立即处理的价值比获得整个完整有效负载更重要,而且更能创建有黏着度的对话,借由实现互动的连续性创建更好的用户体验。
包括文本和图形形式的结果,都可以运用流媒体式回应,也就是说在SageMaker端点所托管的Falcon、Llama 2和Stable Diffusion等模型,都能够将模型推论结果以流媒体的形式回传。官方深入解释,SageMaker即时端点回应流媒体是通过HTTP 1.1区块编码实例而成,也就是说数据会被分成多个区块(Chunked)传输,而非一次性发送整个数据,服务器可以在生成内容的同时立刻开始传输,不必等待所有内容都准备好。
要使用这项新功能,用户需要拥有AWS IAM(Identity and Access Management)角色账户,并具备管理部分解决方案资源的权限,除了网页机器学习开发环境Amazon SageMaker Studio,用户也需要请求相对应SageMaker托管执行实例的服务配额。








