苹果研究团队近日发布一项新研究,指出大型语言模型(LLM)不仅能理解文本,当其接收由音频与动作模型产生的文本描述后,也能有效推断用户正在进行的日常活动。这项研究揭示了苹果在多模态AI感知上的布局方向,也为未来的活动关注、健康侦测与智能场景推论带来更大的想象空间。
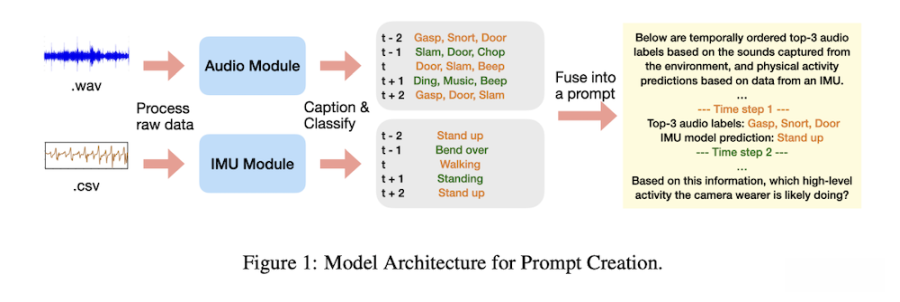
这篇名为《Using LLMs for Late Multimodal Sensor Fusion for Activity Recognition》的论文指出,LLM可用于“后期多模态融合”(late fusion),将来自音频模型与IMU动作模型(加速度计与陀螺仪)的输出进行集成与分析。研究人员表示,这种结合方式能在传感数据不足、无法直接提供完整场景时,协助系统更精准地理解用户的行为。
 (Source:arxiv)
(Source:arxiv)
研究团队强调,LLM在此过程中并没有直接接触音频文件,也没有读取原始传感数据,而是接收由模型自动生成的文本摘要与动作预测结果,通过语言模型的推论能力进行最终判断。这意味着系统能利用更“抽象”的描述进行识别,不必依赖大量专门训练或高成本数据。
 (Source:arxiv)
(Source:arxiv)
研究引用了大规模第一人称视角数据集Ego4D,并从中挑选十二种常见活动,包括吸尘、烹饪、洗衣、吃东西、打篮球、踢足球、与宠物玩、阅读、使用计算机、洗碗、看电视与健身/举重等。研究团队整理出20秒长度的活动片段,再将音频与动作信号输入不同模型,生成文本叙述与活动类别预测,最终再交由LLM进行判断。
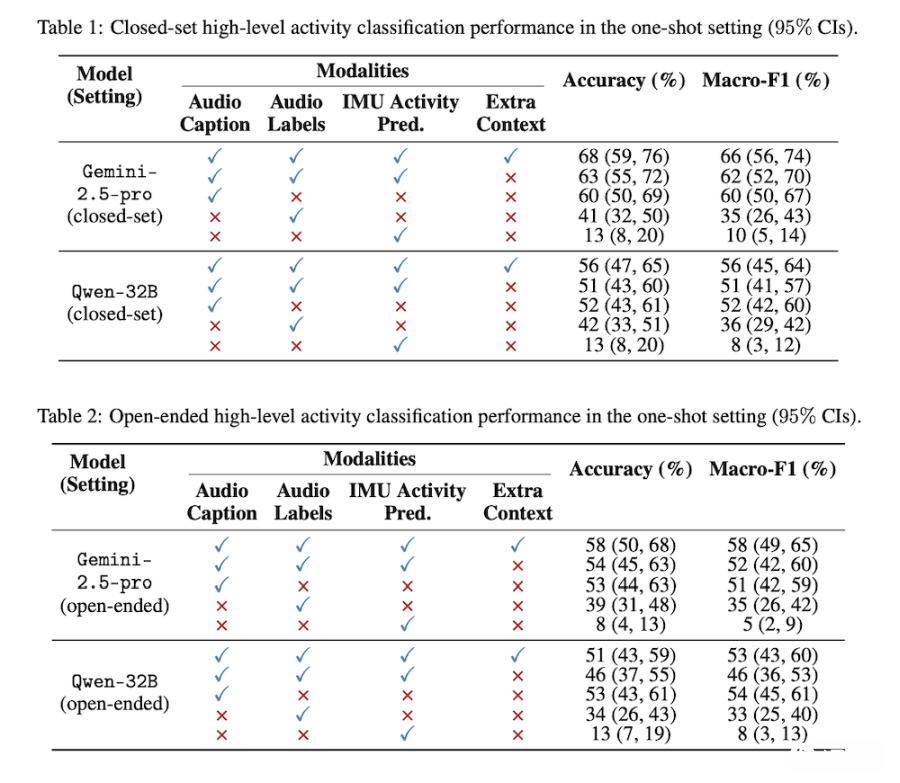
实验采两种设置,一种提供特定的12种活动选项(封闭式),另一种不提供任何选项(开放式)。研究结果显示,无论在零样本(zero-shot)或单样本(one-shot)场景下,LLM均能有效识别活动,F1分数显著优于随机推测。研究人员指出,只要给模型一个示例,其准确度可进一步提升,展现LLM在跨模态推论上的高度潜力。
值得注意的是,这项研究展现一种可能的方向,那就是LLM不必直接看到影音内容,也能借由其他模型生成的文本叙述理解行为,这也可能是苹果未来在隐私与设备端运算间取得平衡的方式。像是在Apple Watch、iPhone或Vision Pro等设备上,系统可在不处理原始音频或大量个人信息的前提下,仍具备更高端的场景理解能力。
研究中也特别提到,通过LLM进行后期融合,可避免为多模态任务额外创建大型专属模型,降低内存负担并提升部署效率。同时,研究结果也有助于推动活动识别、健康监测、智能健身与行为分析等领域的应用,尤其适用于传感数据有限或模型无法进行长期训练的场景。
为推动研究再现性,苹果此次也公开了补充数据,包括Ego4D片段编号、时间戳、提示词以及单样本示例,提供同领域研究者参考。
这项研究虽未明确说明是否会影响苹果的产品规划,但从其多模态融合框架、隐私导向的数据处理方式,以及与健康、场景理解相关的技术方向来看,外界推测此研究结果可能成为未来Apple Intelligence、健康功能或穿戴设备新时代感知能力的重要基础。
(首图来源:苹果)








