
独立的非营利AI研究机构METR(Model Evaluation & Threat Research)上周公布一研究报告,显示资深开发者利用AI来协助解决任务时,所花的时间反而多了19%。
METR是个致力于研究与评估尖端AI模型自主能力与潜在风险的非营利研究机构,它强调评估的独立性及可信度,从未接受来自AI公司的资金,是如今少数可对先进模型部署前执行安全评估的机构之一。
在此次的研究中,METR邀请16名开发人员提供数十个真实且有价值的任务,诸如修复bug、新功能开发或是重构程序代码等,总计有246个任务,并由METR提供每小时150美元的酬劳。此外,这些开发人员平均拥有2.2万颗GitHub星星,所开发或贡献的开源项目平均超过100万行程序代码。
之后由METR随机将这些任务分配至AI组及禁用AI组,收到前者的开发人员多半利用Cursor Pro搭配Claude Sonnet,后者则使用传统IDE,禁用AI辅助工作流程,且每位开发人员都必须录制屏幕画面,同时自行回应所花费的时间。
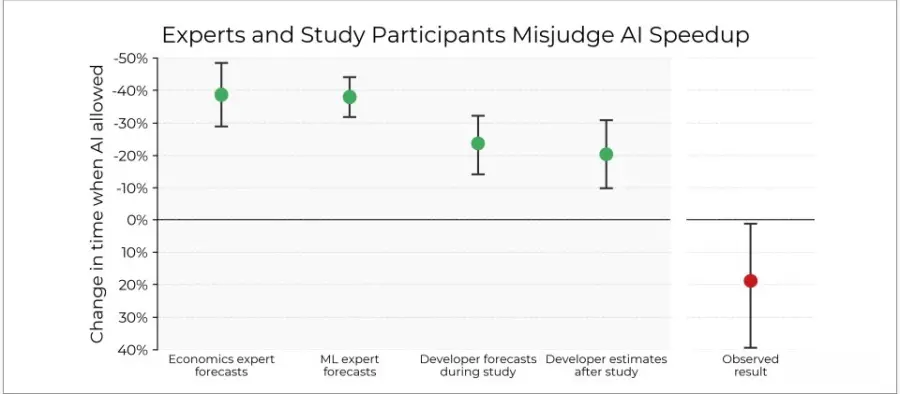
值得注意的事是,开发者在任务开始前原本预期使用AI能让速度提升24%,但实际上,使用AI后平均反而多花了19%时间。更有趣的是,即使任务已经完成、实例明显变慢,他们仍主观认为AI让自己快了20%。这些任务的平均实例时间约为2小时。
METR认为,传统的基准测试常常为了效率或可评估性而弱化了真实性,因此难以对应AI工具及实务中的实际效益,另一方面,开发人员对AI工具的性能存在明显的认知偏差,若要真实掌握AI于部署环境中的影响,未来应依赖更多具现场场景的实测研究,而非仅依赖基准测试及主观印象。








