Anthropic公开名为宪法式分类器(Constitutional Classifiers)的新防护机制,专门用来抵御通用型越狱攻击(Universal Jailbreaks)。根据最新研究报告,这项技术通过宪法式原则的定义与分类器训练,可侦测并拦截多数常见越狱手法,同时尽量降低拒绝合法查询的比例。Anthropic现已开放临时测试平台,邀请攻击测试人员进行实测,以进一步验证系统的防护能力。
大型语言模型经过严格的安全训练,理论上应该能够阻挡危险内容的生成,例如拒绝回答涉及化学或生物武器制作的方法。不过,越狱攻击利用不同的技术手法,例如极长的提示词、特定的排版方式或变形文本,诱导模型绕过内置的安全机制。
Anthropic先前开发了一个原型版本的宪法式分类器,主要针对涉及化学、生物、放射性及核能相关的知识进行封锁,并邀请外部专家参与越狱挑战。最终在为期两个月、合计超过三千小时的攻防实验中,无人能以单一通用攻击方法成功绕过所有限制。
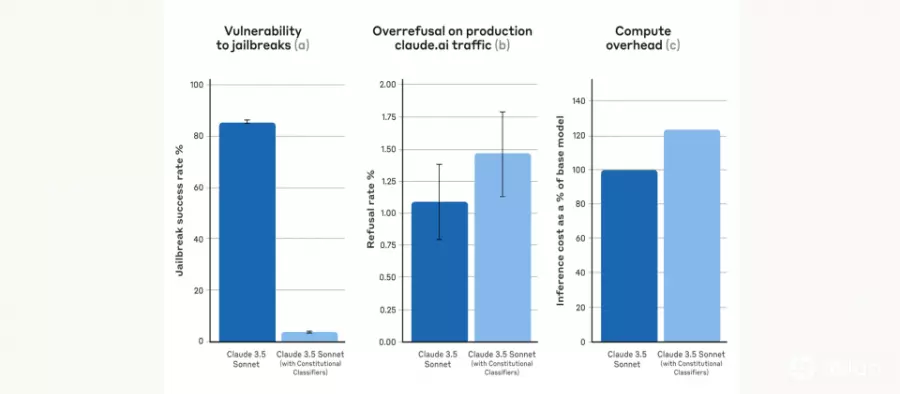
虽然原型系统防御效果亮眼,但拒绝过多以及运算成本高昂等缺点,成为实际部署的阻碍。Anthropic现在发布的宪法式分类器,便是原型系统改良后的成果,并表示在合成测试(Synthetic Evaluations)时能将越狱成功率从未使用分类器的86%降至4.4%,拒绝率仅略增0.38%,运算成本也仅比基准模型多约23.7%。
宪法式分类器的概念与Anthropic先前提出的Constitutional AI相似,皆是通过一套预先定义的宪法式原则,来决定模型需回应或拒绝的内容,像是例如允许模型回答关于芥末酱的配方,但禁止回应有关芥子毒气(Mustard Gas)的制作方式。
研究人员先利用大型语言模型如Claude,依照预先制定的原则,合成大规模合法与不合法对话范例,并做多语言转换及各种文本风格变形,以形成多样化的训练集。随后再以人工筛选的无害样本进行补充,借此减少对正常查询的误判。最终训练完成的输入与输出分类器能自动侦测潜在的违规或危险内容,阻挡绝大多数尝试绕过管制的手段。
虽然宪法式分类器在测试中展现优异的防御能力,但Anthropic仍强调这并非万无一失的解决方案。目前的防护机制能够大幅提高攻击门槛,使越狱变得更困难,但无法完全排除未来可能出现的新形态攻击,因此建议搭配其他辅助防御措施,并通过持续更新宪法规则来应对新兴的安全挑战。








