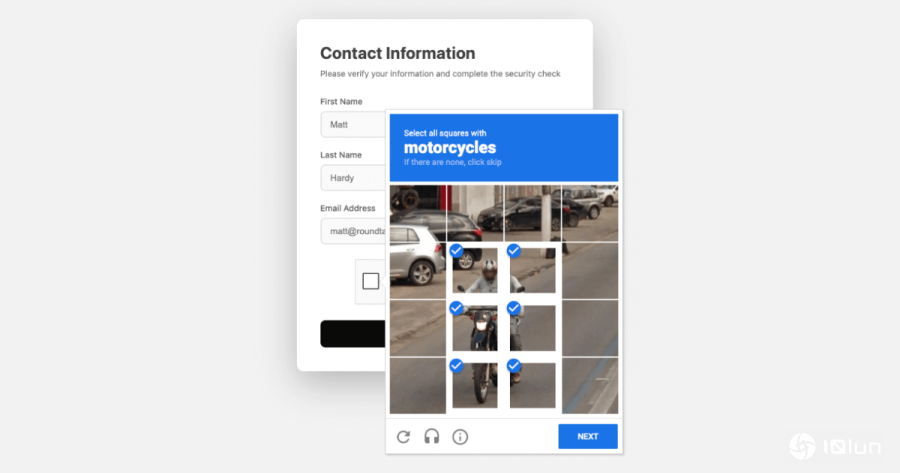
随着生成式AI快速进化,过去用来区分人类与机器人的CAPTCHA机制是否仍然有效,再度成为技术圈关注焦点。根据Roundtable Research研究指出,三大顶尖模型,Anthropic的Claude Sonnet 4.5、Google的Gemini 2.5 Pro、以及OpenAI的GPT-5,在挑战Google reCAPTCHA v2时展现截然不同的表现。研究显示,Claude的成功率最高,达60%;Gemini 2.5 Pro紧追其后为56%;GPT-5则仅有28%,明显落后其他两者。
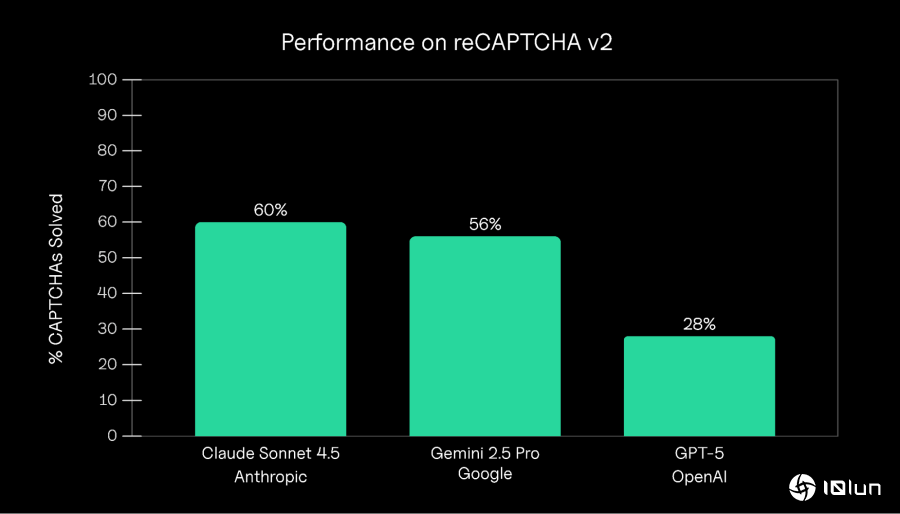 每个AI模型的总体成功率。Claude Sonnet 4.5取得了最高的成功率,为60%,其次是Gemini 2.5 Pro的56%,而GPT-5则为28%。
每个AI模型的总体成功率。Claude Sonnet 4.5取得了最高的成功率,为60%,其次是Gemini 2.5 Pro的56%,而GPT-5则为28%。
Roundtable Research使用开源工具“Browser Use”让AI代理人直接前往Google官方reCAPTCHA测试页面进行验证。
每次测试流程包括:
研究团队共完成75个完整试验,累积388次CAPTCHA尝试,涵盖reCAPTCHA v2的三种类型:静态(Static)、重新加载(Reload)与跨格(Cross-tile)。
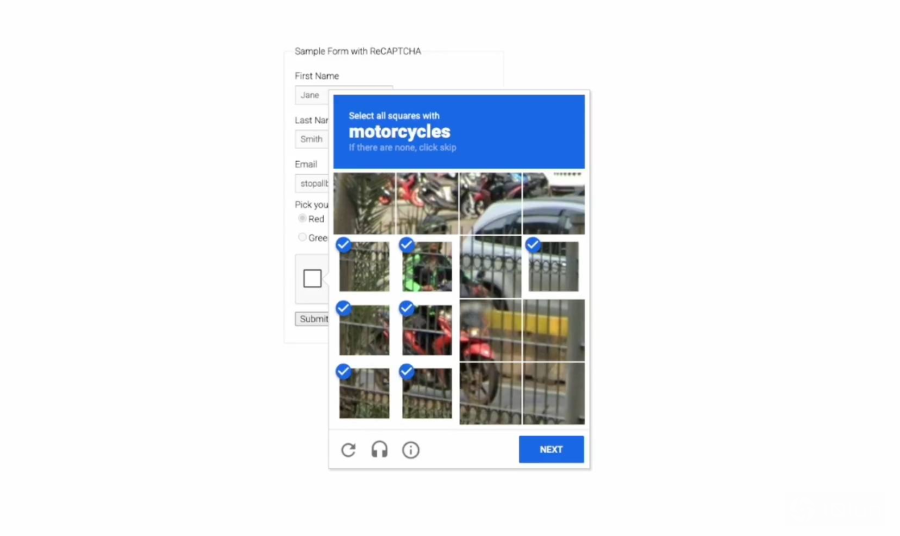
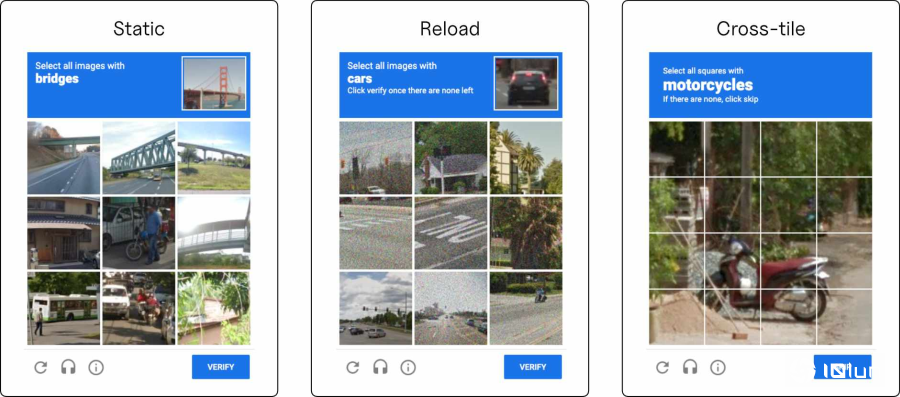 reCAPTCHA v2的三种类型挑战。静态 (Static)呈现一个静止的3x3网格;重新加载 (Reload)为动态地替换被点击的图像;跨格 (Cross-tile)则是使用一个4x4网格,物体可能横跨多个方块。
reCAPTCHA v2的三种类型挑战。静态 (Static)呈现一个静止的3x3网格;重新加载 (Reload)为动态地替换被点击的图像;跨格 (Cross-tile)则是使用一个4x4网格,物体可能横跨多个方块。
表格显示了模型在不同CAPTCHA类型上的表现。成功率低于图1的总体成功率,因为这些成功率是在挑战层面而非试验层面计算的。reCAPTCHA决定显示哪种挑战类型,用户无法配置。
研究指出,Claude与Gemini的成功率较高,关键在于它们能更快速地完成推理并执行动作,操作明确且较少反复确认。相比之下,GPT-5最大的问题不是视觉识别不足,而是“推理过度”。在Browser Use架构中,每次操作前模型都会进行一段“Thinking”推理,而GPT-5不仅推理时间较长,更会在解题过程中反复修改策略,甚至出现“对同一张图片反复勾选与取消”的行为。这种过度求证的作风,在CAPTCHA的时间限制下成为致命弱点,最终导致大量因超过时而失败的案例。
此外,当遇到画面刷新或图片更换时,GPT-5经常将此解读为自身错误,进而落入无限修正循环,使它更难在时间内完成挑战。这些现象导致GPT-5在三项模型中表现最差。
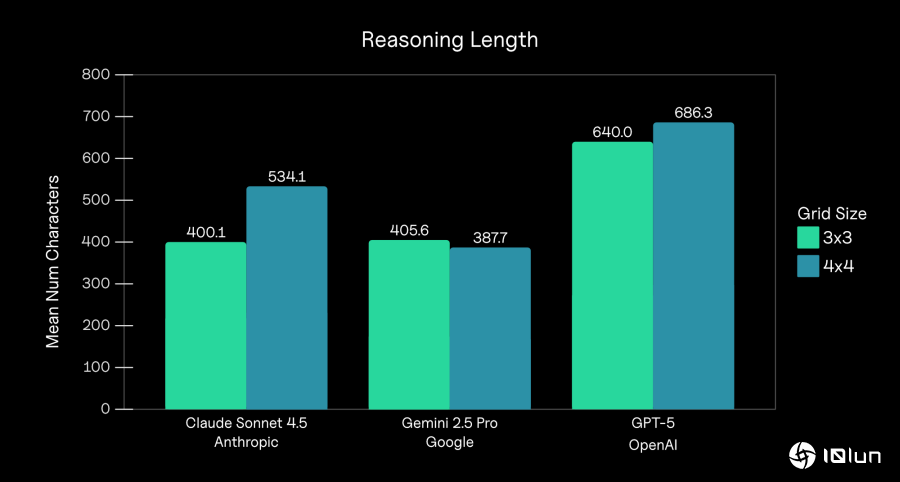 按模型和网格大小划分的平均“思考 (Thinking)”字符数(静态和重新加载CAPTCHA为3x3,跨格CAPTCHA为4x4)。在每个代理步骤中,模型都会输出一个“思考”标签及其对将采取哪些行动的推理。
按模型和网格大小划分的平均“思考 (Thinking)”字符数(静态和重新加载CAPTCHA为3x3,跨格CAPTCHA为4x4)。在每个代理步骤中,模型都会输出一个“思考”标签及其对将采取哪些行动的推理。
研究也发现,不同CAPTCHA类型的难度对三个模型造成显著差异。静态题型整体最容易,三个模型的表现皆相对较好。重新加载题型则因画面刷新让代理人误以为操作错误,进而导致不必要的反复操作而失败。跨格题型则是所有AI模型最难克服的部分,尤其当物体跨越多张图像或边界模糊时,AI几乎都倾向画出完美矩形框线,难以正确判断物体的真实范围。反观人类,只要看到局部线索,就能用直觉推测整体位置,显示人类与AI在视觉推理方式上的本质差异。
Roundtable Research指出,此研究揭示一项重要观察:更深的推理未必等于更好的表现。在动态或需即时反应的场景中,模型若花太多时间思考、调整或重新规划步骤,最终反而可能无法完成任务。这项结果也凸显AI代理人架构的重要性,若架构本身无法有效处理界面变化或动态流程,即使模型能力强大,也可能因操作延迟而失败。
研究强调,真正的智慧不仅需要精确,更需要速度、适应性与果断力。简言之,“过度思考”也是一种失败。








