
鸿海上午宣布,鸿海研究院推出第一版有推理能力的人工智能(AI)繁体中文大型语言模型,未来会导入AI大型语言模型,强化智能制造、智能电动汽车、智慧城市三大平台的数据分析效率。
模型训练过程,鸿海说明,英伟达提供Taipei-1超级计算机及技术咨询,让鸿海研究院使用英伟达NeMo人工智能模型服务,顺利完成模型训练。
鸿海新闻稿宣布,鸿海研究院推出首款繁体中文AI大型语言模型(LLM),开发代码FoxBrain,原为公司应用设计,涵盖数据分析、决策辅助、文书协作、数学、推理解题与代码生成等功能,后续将对外开源分享。
“开源”(open sourced)意指支撑AI的运算代码公开给其他企业和研究人员,让所有人都能用这些技术构建推广产品。
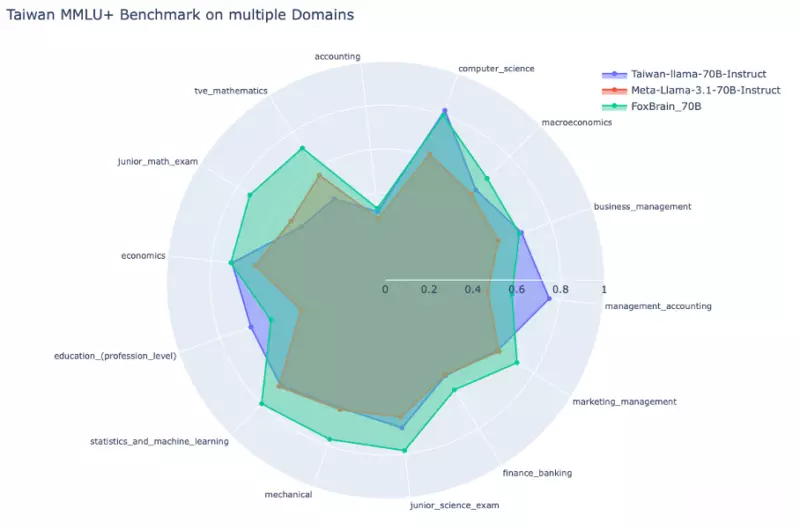
鸿海指出,FoxBrain为鸿海研究院AI推理LLM模型训练成果,展现理解与推理能力,数学与逻辑推理测试表现出色,还能强化台湾用户的语言风格。
鸿海研究院说明,人工智能研究所FoxBrain训练过程用120张英伟达(NVIDIA)H100绘图处理器(GPU),并经NVIDIA Quantum-2 InfiniBand网络扩展,仅花约四周完成,模型训练方式低成本且更具效率。
相关规格与训练策略,鸿海研究院指出,FoxBrain通过自主技术,创建24类主题的数据增强方式与品质评估方法,产生98B词元(tokens)高品质中文预训练数据,上下文处理长度128K token,总计算力花费2688 GPU days,采多节点平行训练架构,确保高性能与稳定性。
测试结果,鸿海研究院表示,FoxBrain在数学领域较基础模型Meta Llama 3.1全面提升,相较目前最佳繁体中文大模型Taiwan Llama,数学测试取得显著进步,数学推理能力超越Meta同等级模型,与DeepSeek蒸馏模型仍有些微差距,但表现相当接近世界领先水准。
鸿海指出,未来会导入AI大型语言模型,强化智能制造、智能电动汽车、智慧城市三大平台数据分析效率,让FoxBrain成为驱动智能应用升级的重要引擎,之后会开源分享,扩大模型运用范围,与技术伙伴共同推动AI制造业、供应链管理与智能决策领域应用。
鸿海表示,FoxBrain成果将于美国时间3月17日登场的英伟达年度GTC大会专题演讲,以“From Open Source to Frontier AI: Build, Customize, and Extend Foundation Models”为主题,首次发布。
(首图来源:鸿海)








