xAI发布新一代大型语言模型Grok 4.1,并同步公开多项评测结果,强调在情感互动、创作能力与查证可靠性上较前一版本全面提升。Grok 4.1已在grok.com、X平台与iOS、Android应用推出,并成为Auto模式的默认模型,目前仅通过这些消费端界面提供使用,尚未通过xAI公开API让开发者串联。
为验证模型稳定度,xAI在正式发布前两周,让Grok 4.1初期版本在grok.com与移动端悄悄负责部分真实流量,再通过盲测比对不同模型的回答品质。依官方数据,Grok 4.1在真人偏好测试中以约64.78%的比例胜出,显示用户普遍更喜欢新版本的回应风格与理解能力。
这次更新并非单纯扩张模型规模,xAI将训练重点放在较难量化的信号,例如语气掌握、人际互动、人格一致性与整体对齐。官方表示,团队以具推理能力的代理式推理模型作为奖励模型,让系统自动评估大量回答并反复微调,目标是在保持推理水准的前提下,使模型能读懂语境、情绪与细微意图。
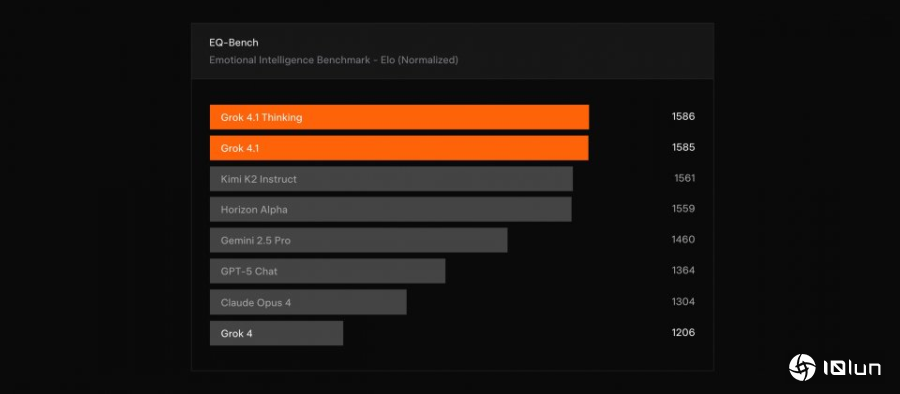
xAI表示,Grok 4.1在EQ-Bench 3情绪商数测试与Creative Writing v3创作评比中,均优于前代Grok 4。官方也正与基准作者合作,准备把完整成绩纳入公开排行榜。EQ-Bench3以多轮角色扮演场景评估模型的同理心与情绪理解能力,而Creative Writing v3则通过多种题材查看模型叙事结构与文风的一致性。
事实性与可靠性是Grok 4.1的另一主打重点,针对非思考模式与搜索工具的组合重新调整判断策略,以降低数据查询任务中的幻觉率。依xAI统计,前一代Grok 4 Fast的整体幻觉率为12.09%,Grok 4.1下降至4.22%。
xAI也引用公开学术基准FActScore,使用约500笔人物传记题目,将模型回答拆解为原子事实并比对可靠资讯来源。在这项测试中,Grok 4.1的FActScore指标为2.97%,前代约为9.89%,分数明显下降,代表模型在长篇叙述中更能避免虚构细节。
在第三方评比中,xAI引用LMArena Text Arena的成绩来说明Grok 4.1的能力。根据官方数据,思考模式的grok-4.1-thinking曾以1483 Elo名列榜首,非思考版grok-4.1则以1465 Elo紧追其后,超越多款竞争模型的完整推理设置,但在最新排行榜,始发布的Gemini 3 Pro立刻登上首位,Grok 4.1系列则下滑至第2与第3名。








