
Alphabet旗下的AI子公司DeepMind正在研究如何帮“生成式视频”生成背景声音,利用视频至声音(video-to-audio,V2A)技术来替这些原本无声的视频加上应有的对话、音效或配乐。
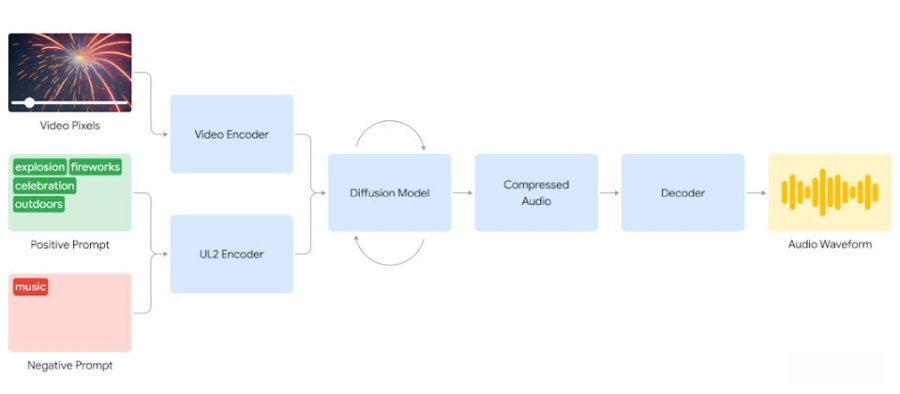
目前DeepMind的V2A技术并不是直接喂入视频就能生成声音,而是结合了自然语言的提示以帮屏幕上的画面配音,兼容于诸如Veo等视频生成模型,并支持包括文件、无声电影等视频内容。
当用户输入音频及文本提示时,V2A便可生成与视频同步的音频波形。它会先将所输入的视频及提示输入数字化,再利用扩散模型反复运算,最终生成一个压缩的声音文件,再由系统将其解码,借以产生与视频画面高度协调的背景声音,完全不需要手动对齐视频及所生成的声音。
在V2A技术的展示视频中,DeepMind团队输入了一个在黑暗中行走的视频画面,再提供“电影、恐怖片、音乐、紧张、混凝土上的脚步声”等文本提示,V2A就能生成恐怖片的背景音乐;还能帮无声的击鼓画面配乐;或是要求它生成搭配画面的海洋音乐。
此外,V2A可替任何视频生成无限数量的音轨,还能选择正向或反向的文本提示,以要求所生成的声音更贴近或远离某些场景。
通过对视频、声音及注译的训练,V2A现阶段已能连接特定的音频与不同的视觉场景,也能对注释或转录文本中的资讯作出反应;DeepMind也正在改善V2A生成结果中关于说话的口型同步能力。








