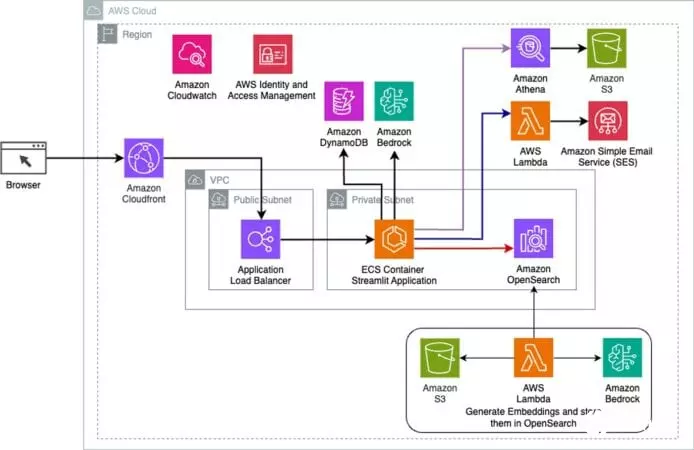
LLM面世以来,越来越多企业都纷纷采用它来提升工作效率。但企业同时都要考虑在提升效率之余应如何控制成本,避免浪费tokens。先前Open AI行政总裁也表示,当LLM解决用户的问题后,用户对LLM表达谢意,便足令开支增达数千万美元。有见及此,AWS于去年12月就推出了Amazon Bedrock智能提示路由 (Intelligent Prompt Routing) 预览版本,并于本月全面推出。该功能可按照问题的复杂性分流到合适的LLM,大致保持答案品质之余,也令成本更低,回应更快。
Amazon Bedrock为每个模型系列提供了默认提示路由器,向更便宜的模型发送更简单的提示,以达到更高性能,减省成本。这些路由器带有预先定义的配置,在特定基础模型上可以开箱即用。另外,也可以自行配置路由器,而目前支持以下系列的LLM模型:
AWS使用了专门及公开数据进行了多项内部测试,以评估Amazon Bedrock智能提示路由。首先,他们使用了成本约束下的平均回应品质增益(ARQGC),这是一个标准化(0-1) 性能指标,用于衡量各种成本约束下的路由器品质,0.5表示随机路由,1盯表示最佳路由效果。其次,测试也比较了与使用该系列中最强的大模型相比,使用智能提示路由所节省的成本。并根据平均记录到第一个token的时间 (Time to First Token, TTFT) 来估计时延优势,有关数据列于以下表格。
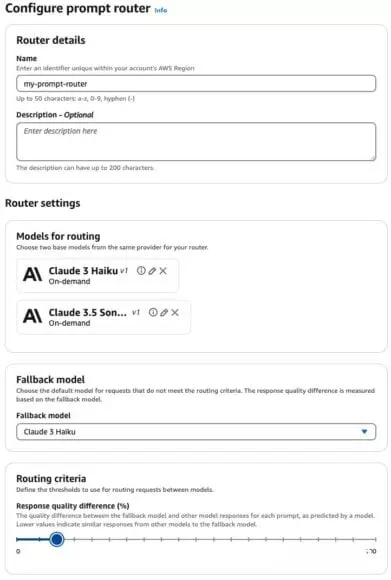
回应品质差异衡量回退模型 (Fallback Model) 与其他模型的回应差异。数值越小表示回应内容越相似,反之亦然。选择以哪一模型作为回退模型十分重要。当使用Anthropic的Claude 3 Sonnet作为回退模型,并配置10%的回应品质差异时,路由器会动态选择一个比起Claude 3 Sonnet的回应品质下降10%的LLM来实现整体性能。相反,如果使用成本较低的模型(如Claude 3 Haiku)作为回退模型,则路由器会动态选择与Claude 3 Haiku相比,回应品质提升10%以上的LLM来实现整体性能。在下图,可以看到Haiku作为回退模型时,回应品质差异设置为10%。
然后,可以在控制台的Playground中使用选用自设的路由器或默认路由器。例如在下图中,我们附加了Amazon.com的一份10K文件,并询问了有关销售成本的具体问题。
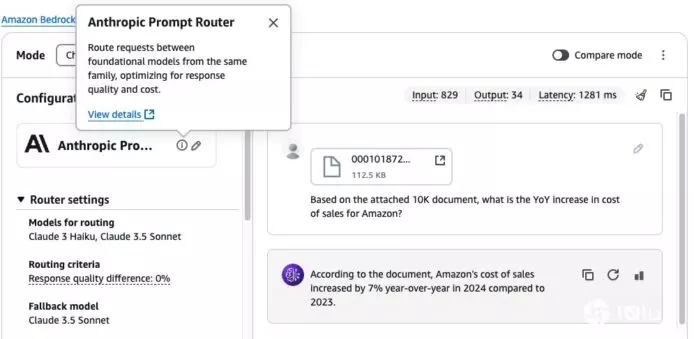
选择router metrics图标就可以看到请求最终经由哪个模型处理。由于这个问题属于较复杂的问题,所以Amazon Bedrock智能提示路由会路由到较强大的Claude 3.5 Sonnet V2,如下图所示。

以上基准测试结果表明,在保持高品质回应和减少延迟优势的同时,智能提示路由在不同模型系列都能显著节省成本。如果想探索最佳配置,可以在配置时尝试不同的回应品质差异数值,分析路由器在其开发数据集上的回应品质、成本和延迟,选择出最适合要求的配置。








