
Google发布针对大型语言模型微调过程,导入用户层级差分隐私的最新研究。研究成果在于兼顾模型性能与用户隐私的前提下,解决过去在大型模型训练时执行用户层级差分隐私(Differential Privacy)噪声过多,导致模型表现受限的问题。
目前开发者在应用大型语言模型时,往往需微调模型提升性能表现,但这些应用大多涉及用户数据,特别是金融、医疗或个性化推荐等对数据敏感度要求较高的场景。传统差分隐私着重于单一样本层级的保护,能降低单笔数据外流的风险,但Google提到,当单一用户贡献多笔数据时,现有方法难以防止判断用户是否参与训练。用户层级差分隐私则进一步保障用户隐私,让攻击者无法从模型推测特定用户的数据是否被用于训练。
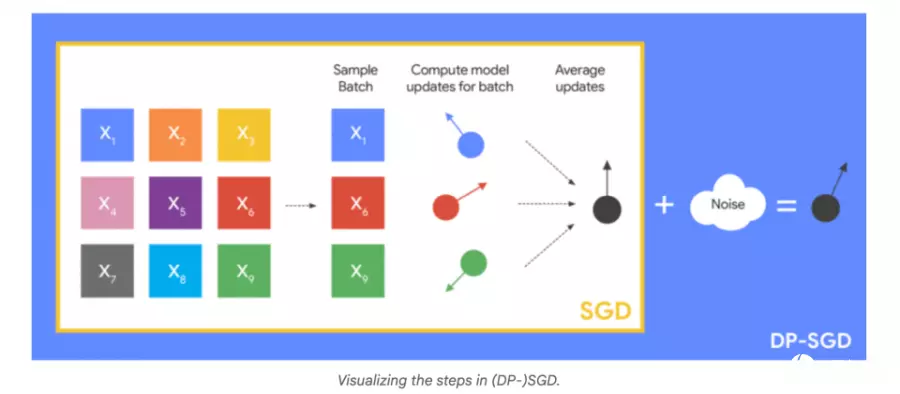
Google团队说明,相较于样本层级差分隐私,用户层级差分隐私在训练过程中须注入更多噪声,才能确保每位用户的隐私,不过噪声增加同时会降低模型学习能力,影响整体性能。此挑战在大型语言模型等需要大量计算资源的训练过程中更为明显。过去用户层级差分隐私大多应用于联邦学习(Federated Learning)等分布式训练场景,对于云计算数据中心大规模模型训练,现有方法则面临实例与性能的挑战。
Google提出的新技术重点,在模型微调阶段的用户层级差分隐私优化策略,针对差分隐私随机梯度下降训练法进行调整。研究团队比较样本层级随机抽样(Example-Level Sampling,ELS)及用户层级随机抽样(User-Level Sampling,ULS)两种方法。这两种方式均通过前处理限制每位用户的最大样本数,以降低单一用户数据对模型的影响,然后进行后续训练。
Google团队发现过去对于应注入的噪人气普遍高估,实际所需噪声可大幅减少,有助于在不影响隐私保障前提增加模型训练成效。此外,研究团队提出用户贡献上限预先设置策略,协助开发者在训练前就选定最佳参数,无需多次试错,进一步降低资源消耗与训练成本。
研究团队在公开的StackOverflow与CC-News数据集上,以3.5亿参数规模的Transformer模型进行测试。实验结果显示,在优化的用户层级差分隐私方法,微调后模型性能优于未经微调的预训练模型,而多数场景,ULS模式可取得较佳性能,仅于部分高隐私需求或计算资源有限的情况,ELS模式才具有竞争力。







