
在2025年OCP高峰会中,Celestica与博通高层以“以1.6T网络技术实现大规模驱动AI”(Driving Al at Scale with 1.6T Networking)探讨目前技术瓶颈,以及博通和Celestica的解决方案。
博通软件产品主管Hasan Siraj指出,在ChatGPT尚未推出时,许多超大规模云计算服务商表示“网络”成为瓶颈,尤其是AI负载的困境。随着AI模型越来越复杂,不只参数量变重要,模型也转往多模态(multimodal),因此对算力的渴求是不会衰退的。
Siraj也预期,未来三到五年内,将出现一个拥有100万个XPU的超级计算机与超级集群,这也使网络越来越重要,因为AI本身是分布式运算系统。他进一步解释,当建设云计算数据中心时,会切割大量CPU资源,分别运行不同的应用程序,由于AI模型运行无法只依靠几个GPU和CPU核心运行,而是需要数十万个运算单元彼此紧密连接,才能进行大规模训练,这也是网络之所以关键的原因。
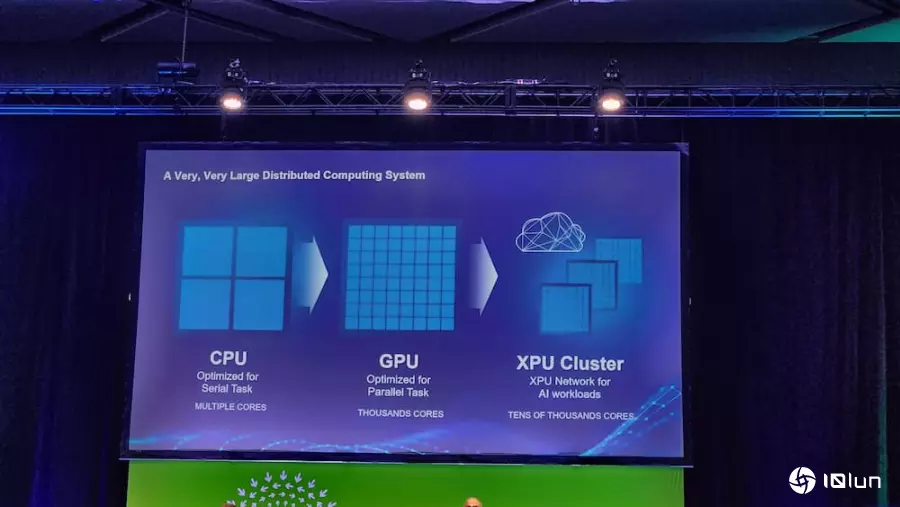
而这个网络,必须具备精确的负载均衡、适当的拥堵控制、可靠的故障切换机制,且在任何情况下都不能牺牲性能与吞吐量,才能确保最佳的工作完成时间。
大规模部署AI集群面临什么挑战?AI扩展主要分成Scale-Up、Scale-Out以及Scale-Across,谈到大规模部署AI集群所面临的挑战。Celestica市场技术副总裁Tareq Bustami指出,首先是解决物理问题的庞大规模,如SerDes的速度要走到200GHz,且信号必须相当稳定;再来是散热,目前已从气冷解决方案开始转往液冷散热,2026年将是成果显著的一代;最后是光通信,如今通过共封装光学(CPO)将光学组件更紧密地集成至芯片级封装(chiplet),虽然相当复杂性,但也见证到进展。
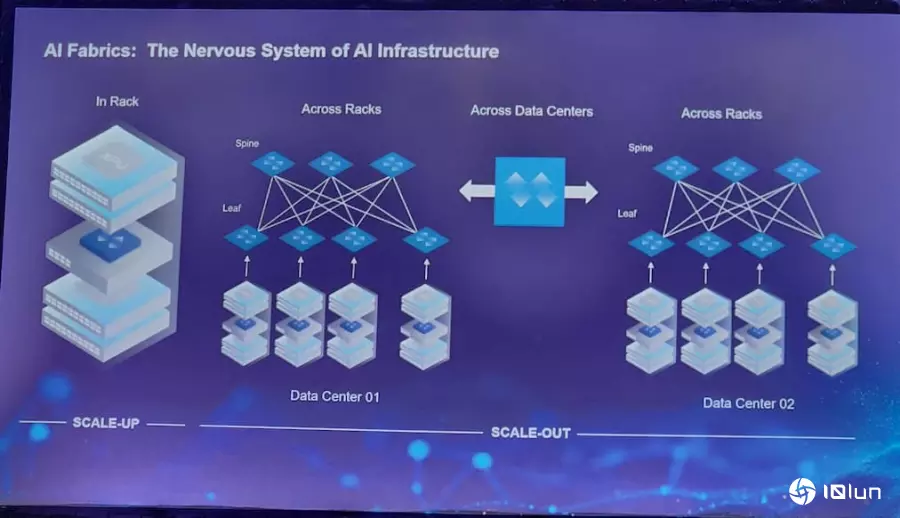
Bustami也强调,所有技术创新都必须在一年内完成,因此“速度”是关键。为了加快开发进程,必须提前通过软件模拟启动软件开发周期,同时制作机械样品进行翘曲分析也很重要。而要解决这些挑战,核心在于“开放标准”(open standards)。他以Linux为例,Linux从诞生到被广泛采用,花了将近十年;如今以Linux为基础的SONiC网络操作系统,也历经多年演进,才逐步在大规模架构中被部署。
 对软件、生态系、标准等最新进展有何看法?
对软件、生态系、标准等最新进展有何看法?Siraj指出,目前业界已完成共识,以太网是构建Scale-Up网络的正确道路,UEC(超以太网络联盟)已有约126家企业、超过2,000名成员参与。虽然现阶段部分专有技术在Scale-Up架构中表现良好,但若要支撑AI产业持续扩张、推动更多数据中心建设,唯有依循“开放生态系”才能实现。

也因此,OCP昨日启动ESUN(Ethernet for Scale-Up Networking)联盟,参与其中的包括12家主要产业龙头,甚至涵盖部分最大型的云计算服务商(hyperscaler)及自研XPU的公司。
博通则于今年六月开始量产Tomahawk 6,这是业界首个100 Tbps交换机,明年初就会看到生产;同时也发布业界首款800G NIC芯片“Thor Ultra”。 Siraj表示,用户可将多达128个800G NIC直接连接至Tomahawk 6,并提供多种外形规格(form factor)以符合不同应用。此外,该NIC也能兼容于其他厂商的交换机,例如NVIDIA或Cisco,在跨品牌环境下依然可维持完整功能,不会发生降级或禁用情况。
Siraj也强调,目前最大规模的AI集群约拥有15万个XPU,要在双层(two-tier)网络拓扑中构建此等规模的网络,唯一能完成的解决方案就是采用Tomahawk 6,因为它能大幅简化网络设计与管理。

最后Bustami也表示,Celestica也与博通尽早期客户紧密合作,构建了多个系统,并于近期推出两款全新的1.6TbE数据中心交换机DS6000与DS6001。这两款产品均支持开源网络操作系统(NOS),以满足高带宽与AI/ML数据中心应用需求。他预期,2026年将会是关键的一年。

(首图来源:科技新报)








