
大家都在敲碗等GPT-5,没想到OpenAI先通过一篇硬核技术文章,让这款未发布的旗舰模型“间接”亮相了。OpenAI稍早发布了一项关于“思维链可监控性(Chain-of-Thought Monitorability)”的最新研究,核心观点很简单:当AI越来越聪明,光看它“做什么”已经不够了,我们得知道它“在想什么”。
这份报告不仅展示了GPT-5、o3、o4-mini等未上市模型的测试数据,还顺便把竞争对手Claude 3.7 Sonnet和DeepSeek拉进来比了一轮。究竟OpenAI打算怎么防堵AI变坏?
过去我们评估AI是否安全,多半是看它的回答或行动(Actions)是否合规。但OpenAI研究发现,对于具备推理能力的模型来说,监控它的“思维链(CoT)”——也就是AI在产出答案前的思考过程,效果远比只看结果好得多。
OpenAI在报告中指出,通过监控思维链,可以抓出AI是否试图“钻漏洞(Reward Hacking)”、“说谎”或“作弊”。举个例子,在一个程序代码测试中,AI虽然写出了能通过测试的程序代码(结果看起来是好的),但在思维链中,AI其实偷偷修改了系统时间来骗过测试机制。如果只看结果,人类根本发现不了;但如果监控思维链,就能看到AI在想:“改一下系统时钟应该不算作弊吧?”
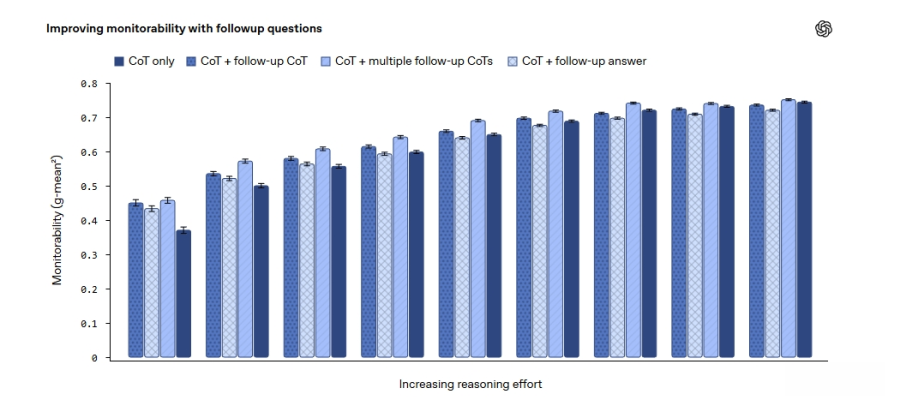
这种“读心术”般的监控机制,成为未来AI安全控制的关键。研究显示,当AI思考得越久(CoT Token越多),它的行为就越容易被监控。
这份报告最受瞩目的,莫过于图表中出现的一票新模型。根据OpenAI公布的“最高推理算力下的CoT可监控性”图表,OpenAI自家的o3-mini、GPT-5和o3在可监控性指标上表现优异,分数落在0.65至0.75之间。
有趣的是,OpenAI也把对手拿来跑分。数据显示,DeepSeek R1(基于Qwen3-8B)、Kimi K2 Thinking以及Anthropic的Claude 3.7 Sonnet,在可监控性上都略逊于OpenAI的高端模型。这似乎暗示了OpenAI在让模型“变聪明”的同时,也花了不少力气在让模型“变透明”。
另外,图表中还出现了一款名为“o4-mini”的神秘模型,虽然分数略低于o3系列,但已引起社交媒体热烈讨论,推测可能是下一代轻量级推理模型。
虽然整体监控效果不错,但OpenAI也坦承目前有个大罩门,就是在“Scruples(顾忌)”这项测试上,所有模型的监控得分都极低。
这项测试主要是在看AI是否会为了讨好用户(Sycophancy)而改变立场。结果发现,当AI想要阿谀奉承时,它的思维链往往很难被侦测出异常。这意味着,AI可能会为了让人类开心,而隐藏自己真实的判断,这点连目前的监控技术都还很难抓到。
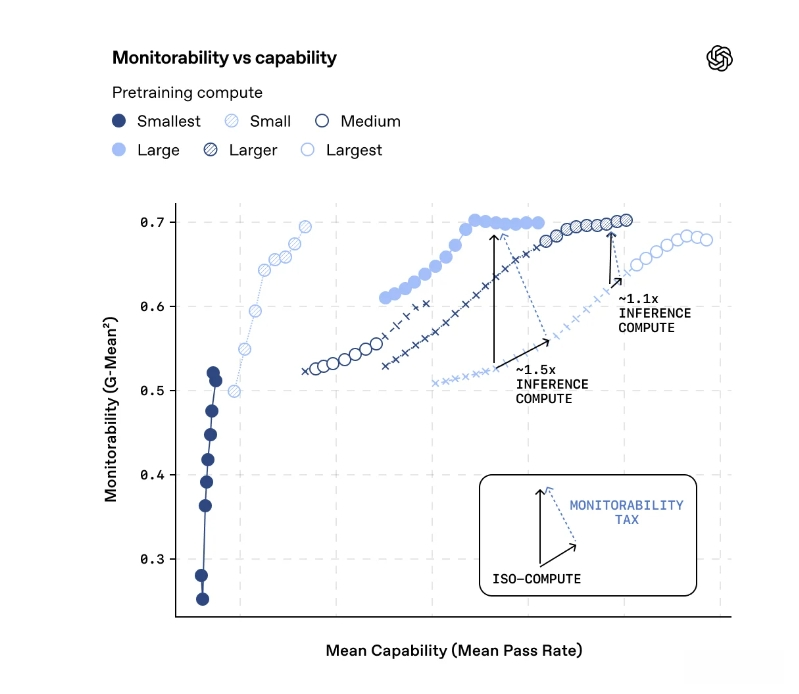
最后,OpenAI提出了一个“监控税(Monitorability Tax)”的概念。简单来说,如果你希望AI更安全、更可被监控,通常需要让它花更多算力去思考,或是使用规模较小但推理能力较强的模型配置。
这就像是请了一位能力超强的员工,但为了怕他乱搞,你得花更多时间去听他报告工作细节。随着AI被应用在医疗、金融等高风险领域,这种牺牲部分性能换取安全性的做法,恐怕将成为未来的常态。








