
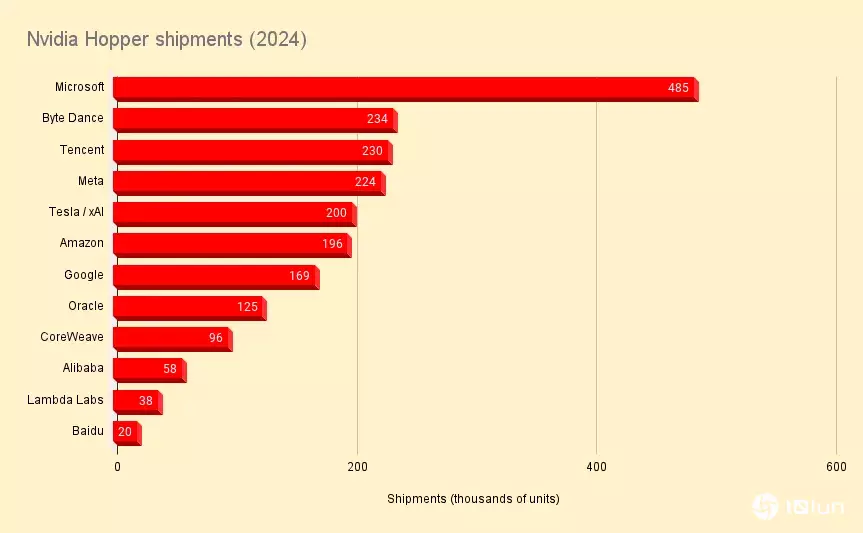
2024年,Nvidia在AI领域仍然占据主导地位,根据Omdia的估计,其Hopper GPU的出货量增加了三倍以上,达到200万以上,其中包括其12家最大的客户。
然而,尽管Nvidia仍是AI基础设施的巨头,但它正面临来自竞争对手AMD前所未有的挑战。在其Instinct MI300系列GPU的早期采用者中,AMD正迅速获得市场占有率。
Omdia预估,2024年Microsoft购买了约581,000颗GPU,是全球最大云计算或超大规模数据中心的客户。其中,每六颗GPU中就有一颗是由AMD制造的。
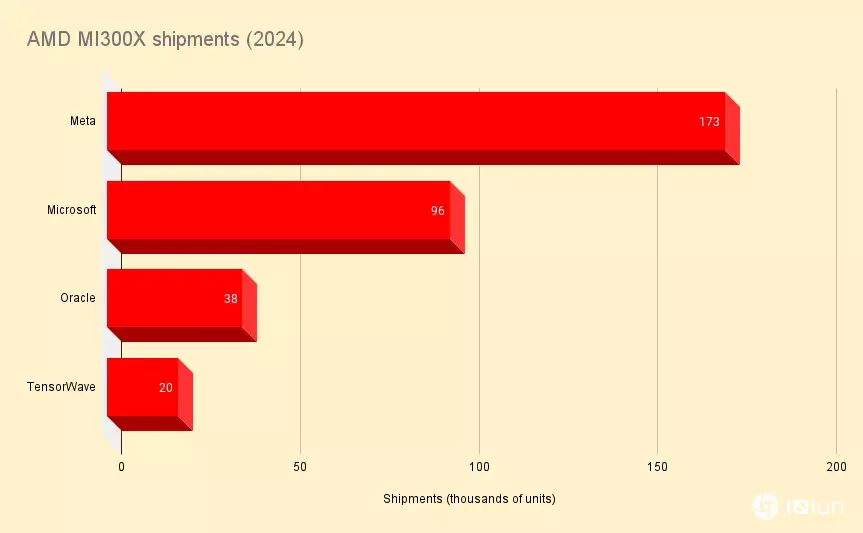
在Meta(根据Omdia的研究,是迄今对这款新推出的加速器采用最积极的公司)中,AMD占GPU出货量的43%,达173,000颗,而Nvidia则为224,000颗。同时,在甲骨文,AMD占据了数据库巨头163,000个GPU出货量的23%。
 2024年,Nvidia仍是人工智能硬件的主要供应商。
2024年,Nvidia仍是人工智能硬件的主要供应商。
尽管在Microsoft和Meta等关键客户中占有率增加,但AMD在更广泛的GPU市场中,相较于Nvidia,仍然显得微不足道。
Omdia的估算关注了来自四家供应商的MI300X出货量——Microsoft、Meta、Oracle和GPU bit barn TensorWave——总计327,000颗。
 2024年,AMD的MI300X出货量仍只是Nvidia的一小部分。
2024年,AMD的MI300X出货量仍只是Nvidia的一小部分。
MD的发展同样引人瞩目,因为其MI300系列加速器才上市一年。在此之前,AMD的GPU主要用于更传统的高性能计算应用,例如橡树岭国家实验室 (ORNL) 的1.35 exaFLOPS Frontier超级计算机。
Omdia云计算和数据中心研究总监Vladimir Galabov说:“他们设法通过去年的HPC场景证明了GPU的有效性,而且我认为这有所帮助。我确实认为市场对Nvidia替代品有渴望。”
究竟这种渴望有多少是由Nvidia硬件供应有限所驱动,目前难以确定,但至少在账面数据上,AMD的MI300X加速器提供了多项优势。这款一年前推出的MI300X宣称,在AI工作负载上拥有1.3倍的浮点运算性能,此外内存带宽提高60%,容量则达到H100的2.4倍。
后两项特点使这款产品对推理工作负载特别具有吸引力,推理工作负载的性能更多地取决于内存容量和速度,而不是GPU可以处理多少FLOPS。
一般而言,如今大多数AI模型都以16位精度进行训练,这意味着运行它们时,每十亿个参数需要约2 GB的vRAM。有了每颗GPU配备192 GB的HBM3内存,单台服务器即可拥有1.5 TB的vRAM。这表示,像Meta的Llama 3.1 405B frontier模型这样的大型模型可以在单节点上运行。反观配备类似规格的H100节点,却缺乏运行该模型所需的完整分辨率内存。而141 GB的H200则不会受到这样的限制,但容量并非MI300X唯一的绝招。
MI300X拥有5.3 TBps的内存带宽,相比之下,H100为3.3 TBps,而141 GB的H200为4.8 TBps。综合来看,这意味着理论上MI300X应该能够比Nvidia的Hopper GPU更快地处理大型模型。
即使Nvidia的Blackwell刚刚开始出货给客户,并在性能和内存带宽方面遥遥领先,但AMD新的MI325X仍然在容量方面占有优势,每个GPU为256 GB。预计明年晚些时候发布的更强大的MI355X将将其推至288 GB。
因此,不难理解为什么Microsoft和Meta这些部署了数百亿甚至数兆参数大型尖端模型的公司,会选择AMD的加速器。
Galabov指出,这一趋势也反映在AMD的指引中,其指引已在每季度逐步上调。截至第三季度,AMD现在预计Instinct系列将在2024财年带来50亿美元的收入。
预期来年,Galabov认为AMD有机会获得更多市场占有率。“AMD表现出色,与客户的沟通良好,且善于坦诚谈论自己的优势和劣势,”他说。
一个潜在的驱动因素是GPU bit barn的出现,如CoreWeave,每年部署数万颗加速器。“其中一些会故意围绕Nvidia替代品构建商业模式,”Galabov提到TensorWave就是这样一个例子。
不止是AMD正在侵蚀Nvidia帝国。同时,云计算与超大规模数据中心正在购买大量GPU,许多也在部署自己的定制化AI硅芯片。
 云计算供应商将在2024年部署大量定制化AI芯片,但重要的是,并非所有这些零件都是为生成式AI设计的。
云计算供应商将在2024年部署大量定制化AI芯片,但重要的是,并非所有这些零件都是为生成式AI设计的。
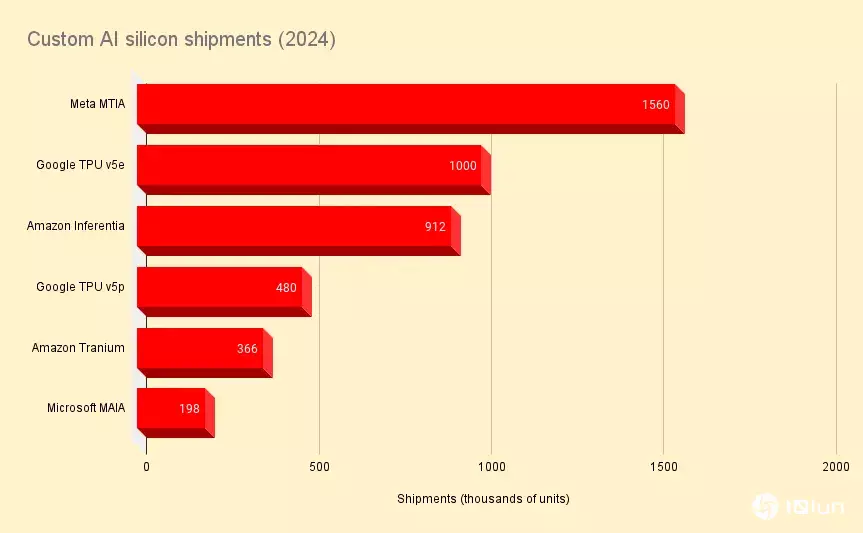
Omdia预估,Meta的定制化MTIA加速器出货量在2024年突破150万颗,而Amazon则订购了900,000颗Inferentia芯片。
这些部分是否对Nvidia构成挑战,很大程度上取决于工作负载。这是因为这些芯片设计用于运行更传统的机器学习任务,例如将广告匹配给用户和产品推荐给买家的推荐系统。
虽然Inferentia和MTIA并非专为LLM专门设计,但Google的TPU一定是,而且已被用于训练包括专有Gemini和开放Gemma模型在内的多款语言模型。
根据Omdia的推测,2024年Google订购了约一百万颗TPU v5e和480,000颗TPU v5p加速器。
除了Inferentia,AWS还有Trainium芯片,尽管名称如此,但它已被重新调整为同时支持训练与推理工作负载。2024年,Omdia预估Amazon订购了约366,000颗这类芯片。这与其Rainier项目的计划一致,该项目将于2025年向模型构建者Anthropic提供“数十万颗”Trainium2加速器。
最后是Microsoft的MAIA芯片,这些芯片在AMD推出MI300X前不久首次亮相。与Trainium类似,这些芯片调整为同时支持推理与训练,这对作为OpenAI的主要硬件合作伙伴以及自身模型构建者的Microsoft来说尤为重要。Omdia认为Microsoft在2024年订购了约198,000颗这类芯片。
Nvidia过去两年惊人的营收增长,无可避免地将焦点放在了AI背后的基础设施上,但这只是更大拼图的一小部分。
Omdia预期,Nvidia明年将难以增加其在AI服务器市场的占有率,因为AMD、Intel和云计算服务提供商正推动替代硬件和服务的发展。
“如果我们从Intel身上学到什么,那就是当你达到超过90%的市场占有率时,增长几乎是不可能的。人们会立即寻找替代方案,”Galabov表示。
然而,Galabov推测,Nvidia与其在竞争日益激烈的市场上争夺占有率,不如专注于扩大总可用市场,让技术更易于普及。
Nvidia推出的推理微服务(NIMs),即设计为构建复杂AI系统的拼图式容器化模型,就是这一转变的例子之一。
“这是史蒂芬·乔布斯(Steve Jobs)的策略。让智能手机成功的是App Store,因为它让技术易于使用,”Galabov说道,“AI也是如此;打造一个应用商店,人们会下载应用并使用它。”
尽管如此,Nvidia仍然专注于硬件。云计算提供商、超大规模数据中心和GPU bit barn已经开始宣布基于Nvidia强大新款Blackwell加速器的大型集群,该加速器在性能上大幅领先目前AMD或Intel提供的产品。
同时,Nvidia已加速其产品规划蓝图,支持每年推出新芯片以保持其领先地位。看来,虽然Nvidia将继续面临来自竞争对手的激烈竞争,但它短期内不会有失去王冠的风险。








