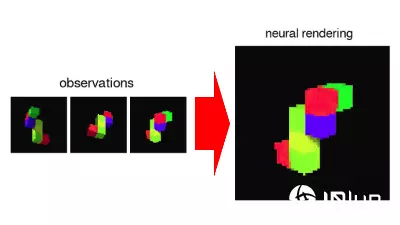
中国科技大厂腾讯在GitHub上公开了全新的AI框架HunyuanWorld-Voyager,能从单张图片生成具一致性的3D场景,并且在该场景中制作镜头移动的视频。

HunyuanWorld-Voyager采用自动化的重建流程,结合相机姿态估计与深度预测,训练数据来自真实拍摄形象与Unreal Engine合成画面,总计超过10万段视频。
其架构包含两大核心:
依输入图片生成RGB与深度对齐的视频串行,确保场景一致性。
通过自回归推论与平滑采样,实现具上下文的场景扩展与不必要点的移除。
因此,模型不仅能从单张图片推导出合理的3D场景,还能生成移动视角的视频,甚至可重建3D点云(point cloud)。


在GitHub上,腾讯公开了多个实例:
用户输入一张静态图片,系统能生成一段镜头在3D场景中移动的视频。
镜头路径可由用户指定,视频效果近似游戏引擎内的场景探索。
生成的视频还能进一步转换为3D点云,尽管粗糙,但能清楚看出场景深度与立体感。