二十几年来,但凡入口页面、商品搜索页面、比价字段、类似商品字段、交叉销售字段、广告商品字段,甚至所谓“个性化推荐”字段,eBay都遵循着同一套电商实行有些年头的传统推荐思维,来推荐商品。
这套传统做法就是商品相似性的推荐,以顾客所选择或正在观看的“主商品”作为比较基准,和不同“候选推荐商品”比较特征,再根据相似性排序,推荐最相近的商品给顾客。
这些年来,eBay不断强化推荐技术,例如从比对单词出现频率的TF-IDF来计算相似性,走到利用NLP模型比对商品标题之间的语义。他们也持续增加不同维度的商品特征,来进一步比较商品不同面向的相似性。甚至,会根据推荐场景,将主商品替换成其他资讯,例如商品搜索条件、顾客最近浏览的商品等。
强化推荐技术时,eBay不惜投入大量时间、人力及硬件支出成本,反复进行大规模、小颗粒度的测试和优化。他们动辄为了一个功能执行上千次实验,或训练多个版本的AI模型,只为了尽可能提升商品推荐关联性。例如,为了强化相似性推荐系统理解商品叙述的能力,他们用了超过30亿条商品标题,先后训练了2个专属NLP模型,再微调一次后,才投入实际应用。
这些做法升级当下,都有带来或多或少的成效。不过,不论这些技术如何演进,归根究柢都是在比较商品之间特征相似性,并且假设,相似性高等于关联性高,关联性高等于顾客购买意愿高。
以30亿条商品标题训练专属NLP模型,强化语义相似性理解
25年来,eBay尝试过各种商品相似性的推荐做法。最常用来比较的商品特征是商品标题。多年来,他们比较商品标题的方法也很传统,利用已经问世50年的词导出现频率算法TF-IDF,以及语义交集联集比较法雅卡尔相似系数等统计学方法,来计算商品标题相似性。
直到2020年代,eBay才开始转而使用NLP模型来进行语义嵌入矢量(Embedding Vector)比对。他们采用当时主流的BERT家族模型。试用了优化版本的BERT模型RoBERTa后,他们发现使用NLP模型来推论相似性的效果明显高于传统统计学方法。为了尽可能提升相似性推论准确度,他们用自家30亿笔历史商品标题及2.5亿条维基百科上的英、德、法、义、西语语句作为训练数据,自行打造一个专属BERT模型eBERT。接着,为了节省运算成本,eBay通过知识蒸馏模型压缩法,以eBERT为老师网络,训练出较轻量的学生网络MicroBERT。
为了再进一步改善MicroBERT模型推论相似性的效果,eBay又加入商品同时点击(Co-clicking)数据,利用InfoNCE损失函数来微调此模型,以缩短相似商品间嵌入矢量距离。微调后模型称为Siamese MicroBERT,用来投入实际推荐场景。
可是,就算用了热门的BERT模型,甚至尝试了多种优化和改良方式,但是,eBay以商品标题数据来训练的模型,仍旧是传统商品相似性思维的推荐结果。
集成图片与文本嵌入矢量,同时比较多模态商品特征
用文本来比较商品相似性后,eBay开始尝试结合图文相似度来比对商品。
以往,他们虽然有利用AI模型生成图片和文本模态嵌入矢量,但两者是独立存储、处理,难以并用。实务上,推荐系统还是以商品标题的文本嵌入矢量,作为主要推荐依据。只从商品标题文本相似性来推荐,可能会发生文本描述接近,但照片不相似,甚至品质低、图文不符,使顾客失去兴趣。
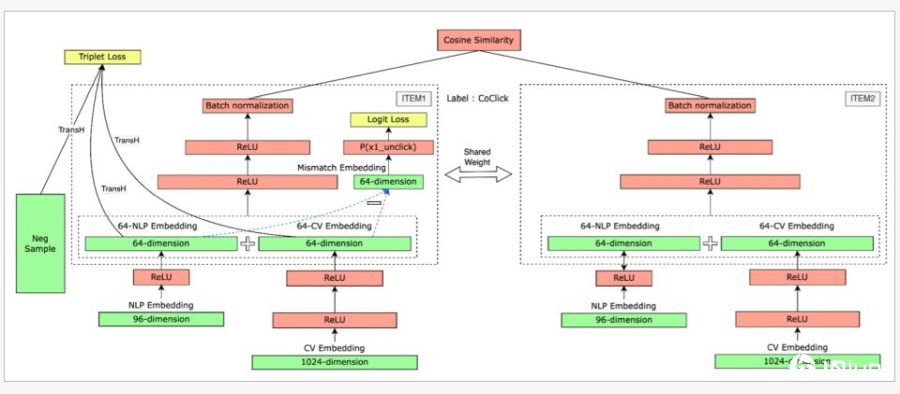
为了有效应用图片矢量于推荐,他们将图和文矢量投影到同一个矢量空间,整合成图文合一的多模态嵌入矢量后,再来比较相似性。他们用TransH知识图谱模型,将图文嵌入矢量投影到同一个超平面,以确保图文嵌入矢量代表同一件商品。接着,再用Triplet loss损失函数,来最小化相似商品的嵌入矢量。经过这些处理,eBay便能并用商品图片及文本嵌入矢量,来比较商品相似性。
他们使用Siamese双塔模型,进行2次嵌入矢量比较,根据相似性来计算主商品及推荐商品同时被点击机率,相似性越高越能提高顾客点击推荐商品机率。
第1次是比较商品自身的图片与文本嵌入矢量距离,来排除图文不符对相似性的削弱。第2次,将主商品与推荐商品,各自的图文嵌入矢量捉对比较相似性。
自此,eBay的推荐模型,从文本推荐,发展到了多模态,文本结合图片的商品特征,来比较商品相似性。虽然eBay推荐技术往前跨了一大步,但仍旧是聚焦在商品相似性,通过商品相似性无法做到的事,就算用了图片结合文本,还是做不到。
转化顾客行为成商品特征,与商品资讯投影到同一个矢量空间
eBay不是不知道顾客数据的重要性,也曾用顾客数据来解决没有主商品的推荐比较,但是,他们受限于商品相似性思维的框架,就算拿到顾客数据,还是回头用来强化商品相似性,而没有真正发挥顾客数据中多样兴趣维度的价值。
像是在eBay首页、“与你最近浏览相似”等字段,有时还没取得顾客浏览的主商品资讯。eBay用了一个号称“顾客导向”的排序模型,分为“深度”与“广度”2部分的架构。在深度面,eBay将顾客浏览及搜索的商品,以及这些行为的频率和顺序,转化为对应商品特征,作为“顾客矢量”,来会充当一般推荐场景的主商品角色,进行比较。
另外在广度面,eBay采用了记忆商品常见销售情况及顾客行为特征,来创建一般性的推荐(而非个性化)的资讯,例如热门商品、关联商品及顾客习惯。综合这2个架构的输出数据,此模型便能在顾客没有点击主商品时,根据顾客以往行为来推荐商品。
虽然他们用了顾客行为数据创建“顾客矢量”来推荐商品,但是,这个“顾客矢量”,只是从顾客行为提取出一系列商品特征,用来与推荐商品进行相似性比较,仍未跳脱以商品相似性为推荐基础的精神。
商品相似性典范限制了思维及推荐效果
eBay对商品相似性的重视根深蒂固,每当要优化推荐方法时,他们第一个想法就是:“如何强化相似性推论?”
比如说,他们有一个收费的相似性商品推荐广告版面,采用梯度提升树(Gradient Boosted Tree)来训练背后的推荐模型,采用了多种排序算法,包括热门度、商品品质及相似性,为了提高广告转化率,放大了热门度对排序的影响。
如此一来,通过这个版面推荐的商品,可能会出现与主商品差异很大的产品,例如高价手表页面,出现了价格和外观都与主商品相差甚远的产品。
当eBay团队发现了这个问题时,就直接选择提高商品相似性的权重,反而没有进一步细究、微调模型中不同因素的权重。他们误以为,只要调整相似性就能让推荐商品更具关联性,也更能引起消费者购买。
甚至,他们刻意排除热门度的影响,微调出一个新模型,来过滤旧模型的结果。新模性移除了所有与热门度有关的排序功能,加入了一个购买机率的目标函数,赋予更高权重给相似性分数高的商品。不过,套用新模型后推荐结果,并没有如预期全面提高顾客的购买率,只有部分商品有效。
这个结果反映出,还有其他需要考虑的影响因素,但是eBay团队发现推荐机制出问题时,习惯把商品相似性视为万灵丹,什么都先从这个角度来思考解法。
eBay这种改善推荐机制的做法,不是在实验“哪一个推荐要素错了”,而只是聚焦在“如何强化相似性权重、强化多少”。这种过度强调商品相似性的思维,局限了他们工程团队的思考空间。
历年来,eBay不断改善推荐机制,确实有效提升了以相似性为基础的推荐方法。不过,Nitzan Mekel-Bobrav坦言,要打破eBay推荐机制面临的瓶颈,不是靠现代化旧有做法。就算相似性推荐做得再极致,此思维原本无法处理的推荐场景,仍然无法处理。
他认为,eBay机制要有所突破,必需要从根本改变思维。首先,定义商品关联性时,要跳脱25年来对相似性的执着,考虑到更多因素。
不只如此,他们还要跳脱平台本位思考角度,否则,当顾客有兴趣的商品不被平台视为同一分类,就算关联性对一般人显而易见,商品相似性推荐系统仍无法推荐。新思维应改从顾客角度出发,尝试理解顾客如何认知自家商品,根据每一个顾客的兴趣来调整商品分类和理解决方案法,才能做到超级个性化的商品推荐。








