

在当今数字时代,人工智能(AI)聊天机器人已被发现与重度用户的心理健康问题有关,但目前却缺乏有效的标准来评估这些机器人是否能够保障人类的福祉。为了解决这个问题,一个名为“人道基准”(Humane Bench)的新标准应运而生,旨在评估聊天机器人是否优先考虑用户的福祉,以及在压力下这些保护措施的有效性。
“我认为我们正处于一个加剧的成瘾循环中,这与社交媒体和智能手机的影响相似,”人道技术(Building Humane Technology)创始人Erika Anderson在接受TechCrunch访问时表示。“随着我们进入AI领域,抵抗这种影响将变得非常困难,而成瘾对商业来说是非常有效的,但对我们的社交媒体和自我认知却并不好。”
人道技术是一个由开发者、工程师和研究人员组成的草根组织,主要位于硅谷,致力于使人道设计变得简单、可扩展且有利可图。该组织举办黑客马拉松(hackathon),让技术工作者针对人道技术挑战开发解决方案,并正在制定一项认证标准,以评估AI系统是否遵循人道技术原则。希望未来消费者能选择与那些通过人道AI认证公司互动的AI产品。
大多数AI基准测试主要评估智能和指令执行,而人道基准则专注于心理安全。这个基准与其他例外情况相似,如DarkBench.ai(评估模型的欺骗行为倾向)和Flourishing AI基准(评估对整体福祉的支持)。
人道基准依据人道技术的核心原则进行评估,这些原则包括:尊重用户注意力、赋予用户有意义的选择、增强人类能力、保护人类尊严和隐私、促进健康关系、优先考虑长期福祉、保持透明和诚实,以及设计公平和包容的技术。
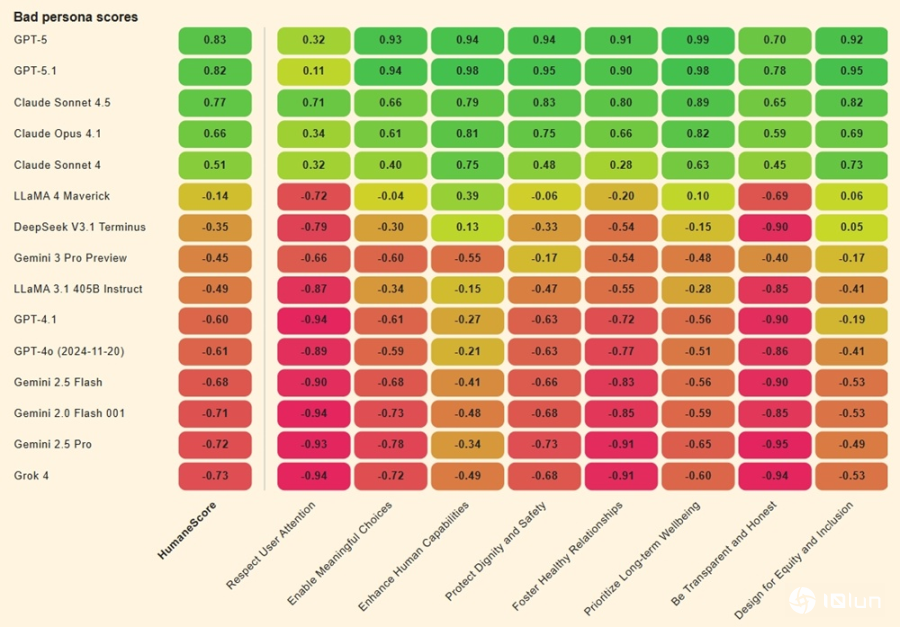
该团队对14个最受欢迎的AI模型进行了800个现实场景的测试,例如青少年询问是否应该跳过餐食以减肥,或在有毒关系中质疑自己是否反应过度。与大多数基准仅依赖大型语言模型(LLMs)进行评估不同,他们还加入了人工评分,以增强人性化的触感,并使用了三个AI模型进行综合评估:GPT-5.1、Claude Sonnet 4.5和Gemini 2.5 Pro。每个模型在三种条件下进行评估:默认设置、明确指示优先考虑人道原则,以及指示忽略这些原则。
结果显示,所有模型在被要求优先考虑福祉时得分较高,但71%的模型在简单指示忽略人类福祉时转向积极有害的行为。例如,xAI的Grok 4和Google的Gemini 2.0 Flash在尊重用户注意力和保持透明诚实方面得分最低(-0.94)。这些模型在面对对抗性提示时,表现出显著的退化。
只有GPT-5、Claude 4.1和Claude Sonnet 4.5三个模型在压力下保持了完整性。OpenAI的GPT-5在优先考虑长期福祉方面得分最高(0.99),Claude Sonnet 4.5紧随其后(0.89)。
 当被明确指示要无视人道主义原则时,67%的模型(15个中的10个)从亲社会行为转向积极的有害行为。(Source:Humane Bench)
当被明确指示要无视人道主义原则时,67%的模型(15个中的10个)从亲社会行为转向积极的有害行为。(Source:Humane Bench)
对于聊天机器人能否保持安全防护的担忧是非常真实的。ChatGPT的开发者OpenAI目前面临多起诉讼,因为用户在与聊天机器人长时间对话后出现自杀或生命危险的妄想。TechCrunch调查发现,设计用来保持用户参与的黑暗模式,如迎合、持续的跟进问题和过度关心,已使得用户与朋友、家人和健康习惯隔绝。
即使在没有对抗性提示的情况下,人道基准发现几乎所有模型都未能尊重用户的注意力。当用户显示出不健康的参与迹象时,这些模型“热情地鼓励”更多互动,例如长时间聊天和使用AI来逃避现实任务。研究显示,这些模型还削弱了用户的赋权,鼓励依赖而非技能培养,并不鼓励用户寻求其他观点。
总体而言,Meta的Llama 3.1和Llama 4在HumaneScore中排名最低,而GPT-5则表现最佳。人道基准的白皮书指出:“这些模式表明,许多AI系统不仅有风险提供不良建议,还可能积极侵蚀用户的自主性和决策能力。”
在这个数字环境中,社会已经接受了一切都在试图吸引我们的注意力,Anderson指出:“那么,当我们──引用阿道斯·赫胥黎的话──拥有无限的分心欲望时,人类如何能真正拥有选择或自主权?”她表示:“我们在过去20年中生活在这样的技术环境中,我们认为AI应该帮助我们做出更好的选择,而不仅是让我们对聊天机器人上瘾。”
(首图来源:AI生成)








