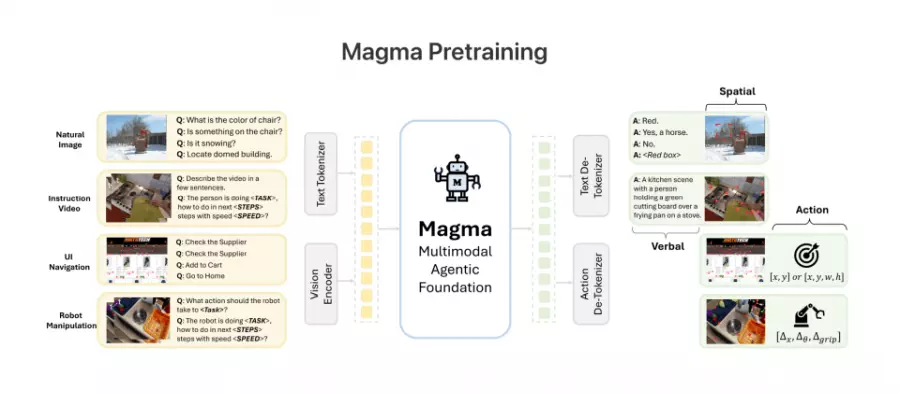
微软研究院发布Magma,这是一款针对多模态人工智能代理设计的基础模型。Magma具备视觉与语言理解能力,能够直接执行UI操作与机器人控制,突破了传统视觉语言模型仅限于静态理解的限制。微软强调,Magma单一模型即可处理数字与物理环境中的互动任务,且不需特定领域微调,就展现出优于现有专用模型的性能。
Magma的核心技术是Set-of-Mark(SoM),通过标记可操作对象,如UI按钮或机器手臂,让人工智能能够准确理解形象中的互动元素,进而做出适当动作,像是Magma能够在UI操作中识别可点击的按钮,并执行指令来完成复杂的操作流程。在机器人领域,SoM让人工智能能够判断环境中的物体位置与特性,控制机械手臂稳定执行物品抓取、移动等任务。
此外,Magma也运用Trace-of-Mark(ToM) 技术,该技术重点在于学习时序动作,借由标记形象中的移动轨迹,让人工智能理解对象在时间轴上的变化。ToM让Magma能够预测未来动作,例如判断机器手臂在操作过程中的最佳移动路径,或分析视频中人物的行为模式,更精确地规划下一步动作。相比传统逐帧预测方法,ToM使用更少的Token,但能捕捉更长时间范围的变化,提升人工智能在动态场景中的决策能力,并降低环境噪声的影响。
在多项基准测试中,Magma表现优于现有模型。在UI操作领域,在Mind2Web和AITW测试中完成高准确率,证明其能够操作复杂的网页与移动设备UI。在机器人操控方面,Magma在WidowX和LIBERO测试超越现有的机器人视觉语言模型OpenVLA,成功执行软件操控与拾取放置任务,并在已知与未知场景下展现良好的泛化能力。
Magma的强项在于零样本与少样本学习能力,能够直接应用于未见过的环境,而不需要额外微调。测试显示,Magma在UI操作与机器人任务中,都能够在零样本场景下执行完整任务。除了UI操作与机器人应用,Magma在视觉问答、时序推理等任务上也表现出色。在空间推理测试中,其表现超越GPT-4o,微软提到,空间推理评估对于GPT-4o来说仍然是具有挑战性的问题,但Magma尽管预训练数据少得多,却能更好地回答这类问题。








