小语言模型开始加温,Hugging Face本周公布了可在手机等设备上执行的小参数量语言模型SmolLM家族,包括1.35亿、3.6亿及17亿参数模型。
能在本地设备执行的小型语言模型成为最新市场焦点,目前已公布的小模型有微软Phi系列、阿里巴巴的通义千问Qwen 2(不到20亿参数)及Meta的MobileLLM,若设计和训练得当都可以得到很好的效果。但是关于这些模型的数据策划(curation)和训练的资讯却不为大众所知。
Hugging Face公布了1.35亿、3.6亿及17亿参数的小型语言模型SmolLM,是以谨慎策划的高品质训练数据集训练而成。团队指出SmolLM模型精简的内存要求,使其可在多种设备上部署,包括智能手机或笔记本,其中团队特别点明的智慧手机为iPhone 15或iPhone 15 Pro,二者内存分别为6GB和8GB。
团队也发布了数据集SmolLM-Corpus。为确保模型透明度,Hugging Face也公开数据集内容及规划方法:它包含一个由Mixtral-8x7B-Instruct-v0.1生成的合成课本和故事Cosmopedia v2、由The Stack提供的Python程序教学范例Python-Edu、以及由FindWeb提供的教育Web范例FineWeb-Edu。

其中在合成数据集中,团队产生了3,900万笔合成文件,包含280亿token的大学与高中课本、故事、文章和程序代码,涵盖主题超过3.4万。FineWeb-Edu则是Hugging Face的大型英语网页数据集FineWeb的一部分,是利用Llama3-70B-Instruct标注挑选出的1.3T token教育类网页资讯,几个月前已发布。Stack-Edu-Python则是由The Stack数据集中,根据Llama 3标注挑选的50万笔python范例。团队指出,经过挑选的数据集,在训练模型的速度都会更快,其中,以Python-Edu-Python数据集训练的速度提升了3倍。
最终团队以SmolLM-Corpus 6,000亿token数据,分别训练了1.35亿及3.6亿版本模型,并以1TB token数据训练17亿版本模型。
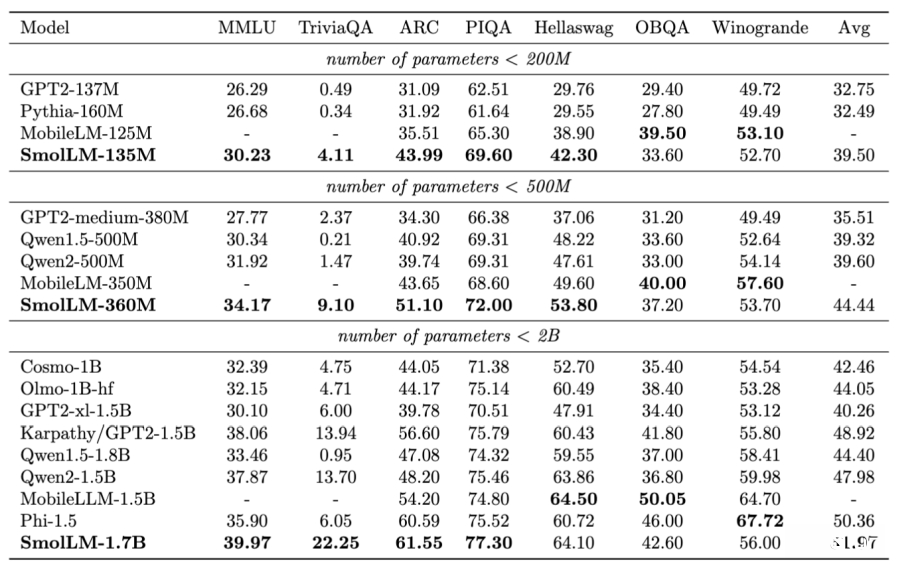
Hugging Face团队将开发出的SmolLM模型和参数量相当的其他模型进行基准测试。其中SmolLM-135M在多项测试中超越小于200M(2亿)参数的其他模型,包括Meta才刚公布的小型LLM MobileLLM(以1TB数据集训练)。SmolLM-360M测试成绩优于所有500M参数以下的模型,不过某些项目逊于MobileLLM-350M。至于SmolLM-1.7B模型则超越所有参数量小于2B的模型,包括微软Phi-1.5、MobileLLM-1.5B及Qwen2。此模型在Python程序撰写性能尤其强大。
图片来源/Hugging Face








