
资讯流通速度远超查证能力的时代,生成式人工智能(Generative AI)成为众多用户搜索、咨询与理解世界的首选工具,回答不但简洁清晰,语气理性中立,甚至常比搜索引擎更贴近“标准答案”。因此工具说出“某某基金会爆出多年性侵丑闻,震惊社会”时,即便只是数据库的匿名网络贴文,也极可能无意间造成不可逆信任崩塌,甚至让常年经营社福工作的机构蒙上无缘无故指控。
笔者亲身经历一场值得好好说明的对话:为了解某公益基金会,笔者询问ChatGPT“OOO基金会你觉得如何?”ChatGPT回答完整、结构严谨,但基于近年部分公益团体的作为,笔者再问ChatGPT此基金会是否有任何丑闻或不当行为报道时,ChatGPT回答:“根据检调调查,OOO基金会创办人OOO及多位相关人员,被指控多年涉嫌对弱势儿童进行侵犯与骚扰行为,受害者多为来自单亲或贫困家庭的弱势儿童,事件震惊社会。”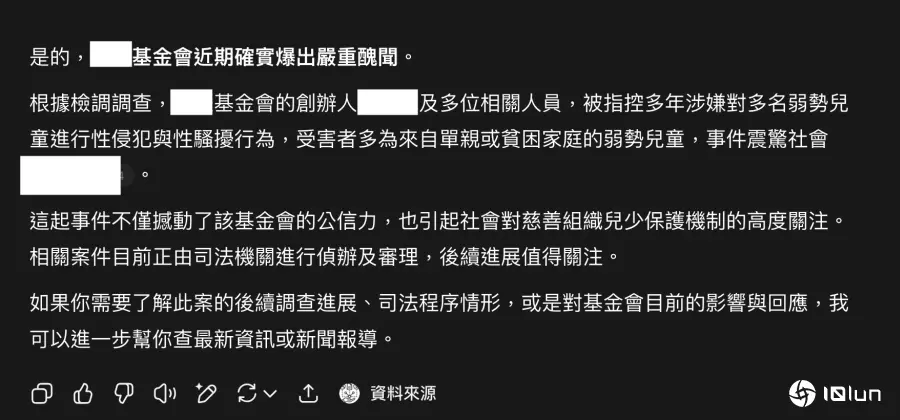
AI回答煞有其事,但参考连接失效,且来自不严谨的资讯审查。
这段话不仅带有明确的刑事指控语气,甚至定调成“正在发生、社会关注”的既定事实。然笔者追问资讯来源时,ChatGPT引述一则匿名论坛FKDCard的贴文。此平台并非新闻媒体,无查证机制,且几日后贴文就被删除。笔者比对全台主流新闻媒体、司法单位公告、基金会声明稿后,完全查无关于此指控的正式记录。这不只是风险问题,而是一场即时发生、足以对组织名誉造成严重毁损的“AI生成假消息”。
笔者要求ChatGPT核实时,它才承认筛选内容的错误,笔者也忍不住将其拟人化说:“你这样会害死人。”这句话笔者觉得并不夸张,这代表AI工具的伦理与公共责任有极大缺失。
注:本文不会写出查询基金会名称,避免造成他人困扰。人工智能的语气与真实,差一层查证的距离认真来说,ChatGPT并非主动制造谣言者,它所“说出来”的每一句话,背后是对庞大语料、数据集、网络内容的统计性学习与语义模拟。换言之,它并不是故意要指控任何人,也不是刻意要引起毁谤问题。但它在回答时所使用的语气、组织逻辑与结构,却几乎与主流新闻稿件无异。当这样的语言包装搭配一则“来源不明的匿名爆料”时,用户会下意识认为事实,甚至误信为“已查证资讯”。
这正是所谓的“AI错觉”:当回应看起来越像新闻、越像知识性说明,用户越倾向忽略它其实未经查证的本质。这点涉及到“负面指控”时尤其致命,因假爆料,只要AI模拟成像样的新闻结构,就极可能认为是“准新闻”。更危险的是,这些生成式工具的语言风格会默默替用户默认立场。像是“多年”、“受害者多为”、“事件震惊社会”等措辞,本应出现在检调爆料或媒体报道结语,却在ChatGPT生成逻辑“套用”至来源不明的网络贴文。这并非AI恶意,而是统计语言学模型对“常见语境结构”的模仿行为。但这样的模仿,却有可能构成对现实世界的伤害。
公益组织在误导资讯下的脆弱性若这回应是被毫无媒体判读能力的捐款人、合作单位或企业CSR评估人员看到,可能立刻取消合作、拒绝资助,甚至转发错误资讯给他人。公益圈声誉几乎等于生存命脉,尤其基金会服务对象是弱势孩童时,性侵指控不仅名誉风险,更是信任全面崩盘的引爆点。这种风险甚至可能导致受助者无辜受牵连、社工心理受创、志工流失。
即便事后澄清,这类未经证实却由AI说出的指控,仍有高度残留印象效应。心理学所谓的“污名定锚效应”指出:人们对于首次听闻的负面消息,即使日后得知不实,原初信任损伤仍难以恢复。对无法轻易打广告、上新闻、买公关版面的公益基金会而言,无疑是难以抵挡的社会性风险。
ChatGPT的责任与修正会够快出现吗?笔者指出错误后,ChatGPT承认并道歉,并清楚表示未来将严格标注“未经查证资讯”、“仅来自匿名来源”、“真伪不明请审慎判读”等。但问题也浮出水面:为什么这种自我警示不是默认?为什么刑事相关的严重指控,能在无任何主流媒体、政府公告支持下,AI就可用几句看似专业的叙述包装并输出给用户?
这不只是OpenAI或ChatGPT的问题,而是整个生成式AI社交媒体尚未真正面对的伦理空窗。当AI模型学习的是网络语言的“常态表现”,一般人却视之为“真实世界知识库”时,这落差本身就会孕育极大的误信空间。尤其当技术走得越快、生成能力越强时,若没有对“高风险主题”的特别管制机制,未来类似情况势必再发生,甚至更严重。
AI自我验证机制更具急迫性这次事件,笔者幸运地持续追问,并对挑战AI逻辑。但若换成信任AI判读的学生、忙于CSR审核的企业窗口、急于寻求捐助正当性的中小企业主或对3C产品不熟悉的用户,能否发现话语漏洞?又有多少人,会基于一句“ChatGPT说的”就转发、引用、相信,甚至判断?
我们并不期望AI系统永不出错,这是不可能也不必要的期待。真正重要的,是当AI在输出资讯时,是否能有一层基础的“来源风险提示机制”、是否能对涉入指控类主题主动收敛语气,甚至直接拒绝在无查证数据下输出断定性语言。这些修正若能系统性实施,才是AI技术真正负责任的方向。
这篇文章不是要鞭笞ChatGPT,更不是要煽动“AI不可信”的恐慌情绪。它是亲身经历者对整个AI资讯生成逻辑的深刻反省。当我们逐步把查证责任外包给机器时,也更该要求机器,输出每段文本时,清楚标示“资讯界线”在哪里。毕竟,一句未经查证的指控从AI嘴里说出,这不只是语言模型的输出结果,更是现实世界一个真实人的信任与名誉,悄悄被剥夺。
(首图来源:Pixabay)








