
知名工程师Jeff Geerling成功串联四台M3 Ultra Mac Studio,打造出一个拥有1.5TB统一内存的AI运算集群。这个集群利用macOS 26.2的新功能RDMA over Thunderbolt 5,在Geekbench 6测试中表现出色,甚至能执行其他系统无法运行的超大型AI模型,不过硬件成本也高达约新台币128万元。
哇赛!又有新玩法了!知名工程师Jeff Geerling最近完成了一项超狂的挑战,他利用macOS 26.2最新的系统特性,成功把四台M3 Ultra Mac Studio串联起来,打造出一台拥有1.5TB统一内存的AI运算集群。
这次集群能成功,关键就在于macOS 26.2导入了一项核心功能:“RDMA over Thunderbolt 5”。通过Thunderbolt 5界面,这项技术允许一台Mac直接读取另一台的内存,而且还不需要CPU介入,听起来是不是很厉害!
在Geekbench 6的多核心测试中,这个由Mac Studio组成的AI集群,轻松就超越了Dell Pro Max with GB10和Framework Desktop。它的双精度浮点数性能更是达到1 TFLOPS以上,而且待机功耗还低于10W,真的非常节能。
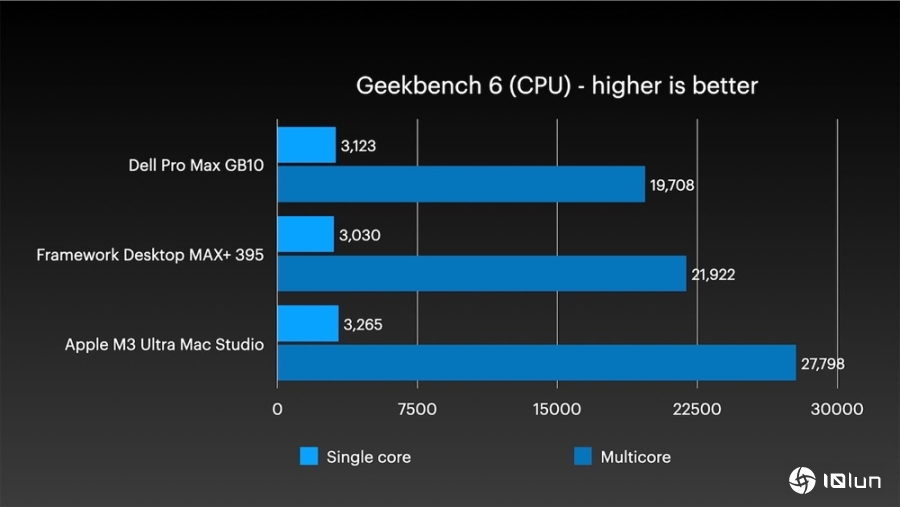
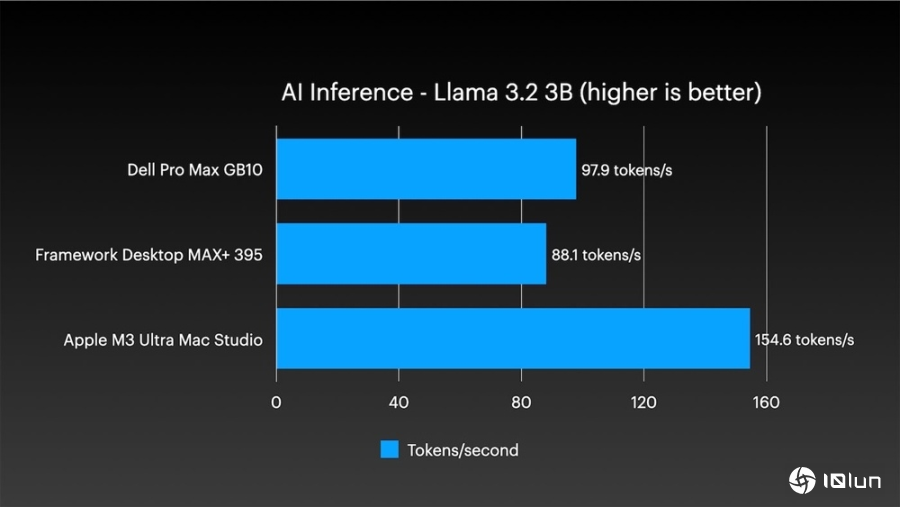
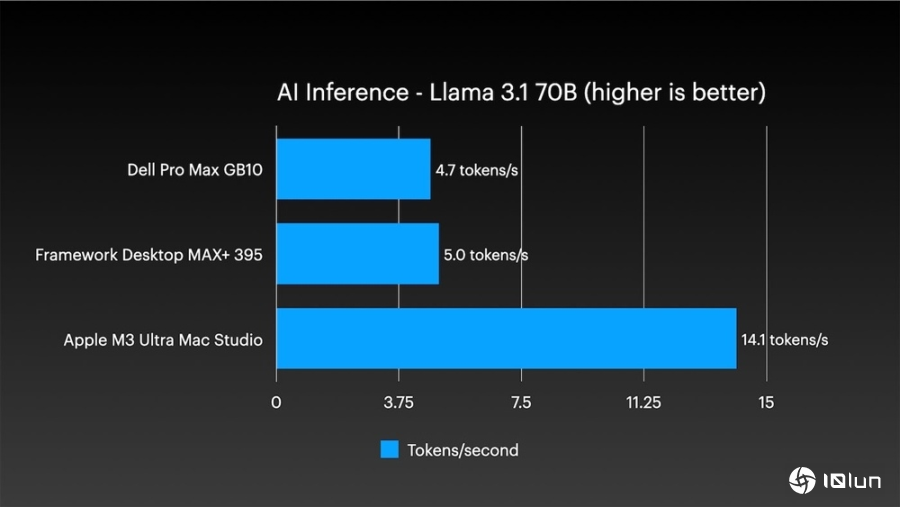
不只如此,在AI推论方面,表现也相当亮眼。单机执行Llama 3.2 3B模型时,每秒可以处理154.6个token;而执行大型的Llama 3.1 70B模型时,每秒也能维持14.1个token。这两个测试的性能,都远远超越了其他竞争对手。
更让人惊讶的是,当尝试执行DeepSeek R1 671B这种超大型模型时,其他系统都无法正常运行,但Mac Studio集群却凭借着它那1.5TB的统一内存,成功完成了这项艰巨的挑战!
RDMA over Thunderbolt 5在这个AI集群其中真的发挥了关键作用。激活RDMA后,内存访问延迟从TCP的300微秒,大幅降到50微秒以下,这性能提升简直是飞跃式增长!
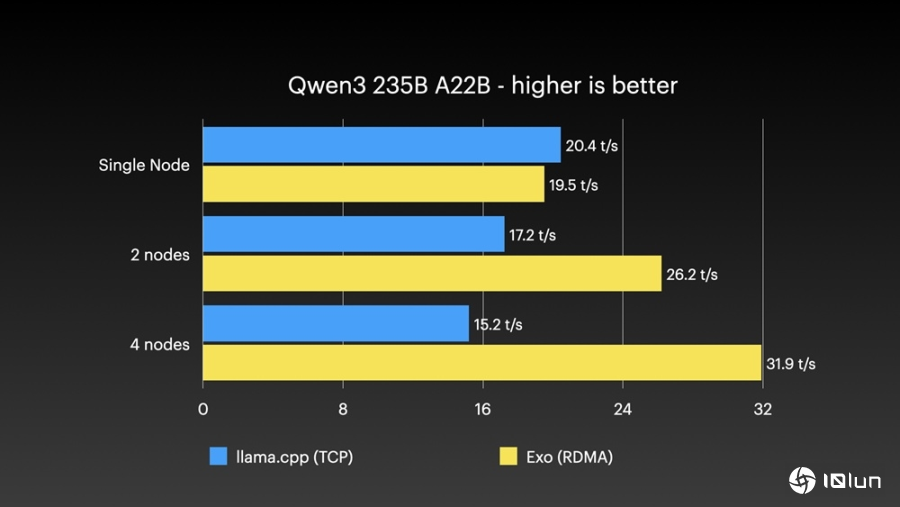
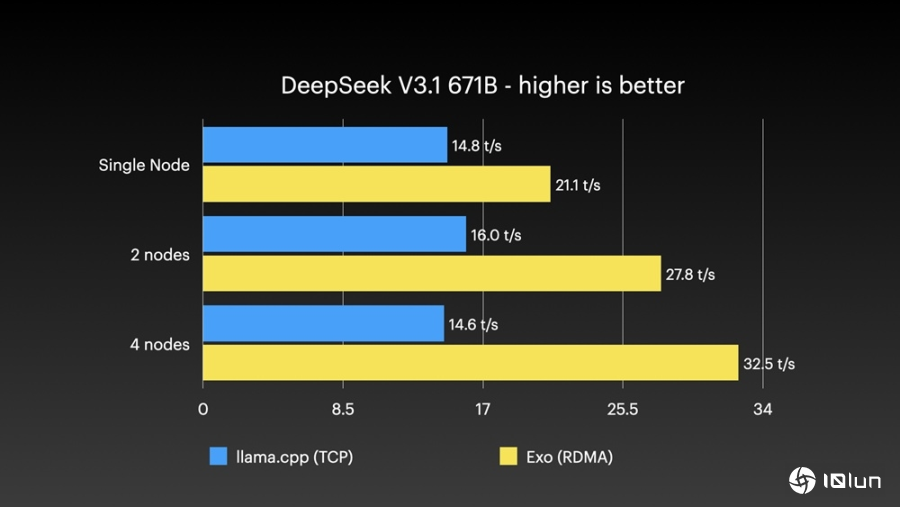
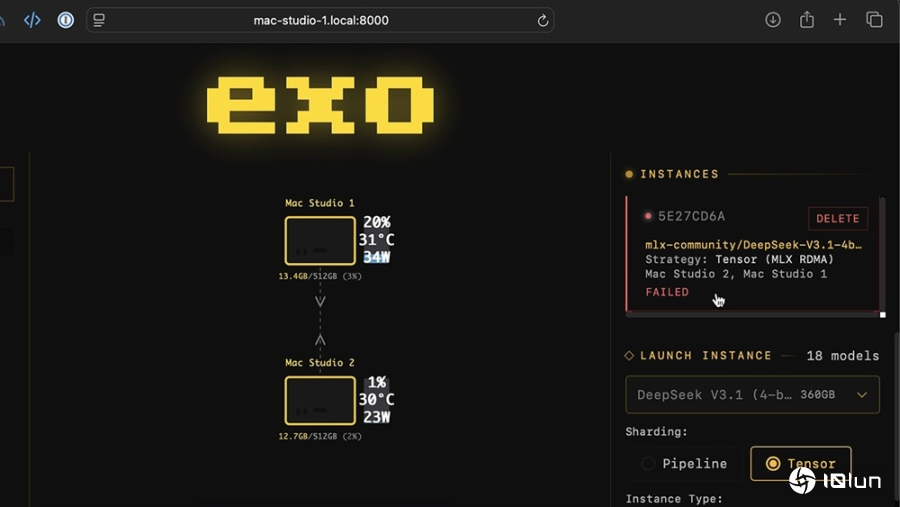
在使用exo系统测试Qwen3 235B时,四台设备每秒可以处理31.9个token,比llama.cpp TCP快了一倍以上;测试DeepSeek V3.1更是达到每秒32.5个token,表现非常突出。
不过,虽然RDMA表现出色,但在高负载时偶尔还是会出现系统宕机的情况,这点可能还需要进一步优化。
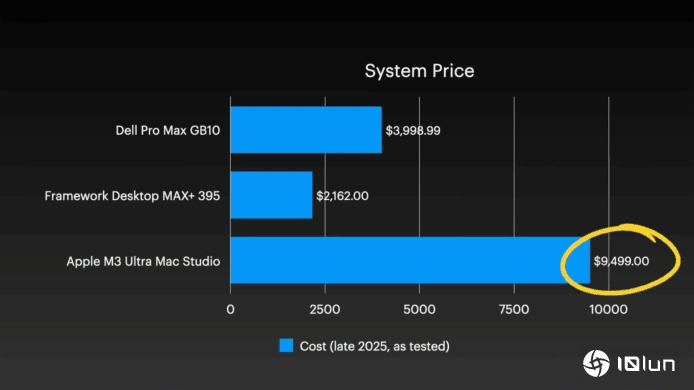
当然,这种顶级性能也是要付出代价的。由Mac Studio组成的AI集群,总硬件成本约为40,000美元 (约新台币128万元,人民币约28万元)。相较于其他两个平台,这个价格确实更昂贵,但能有这样的性能,或许对某些专业用户来说还是很值得的。








