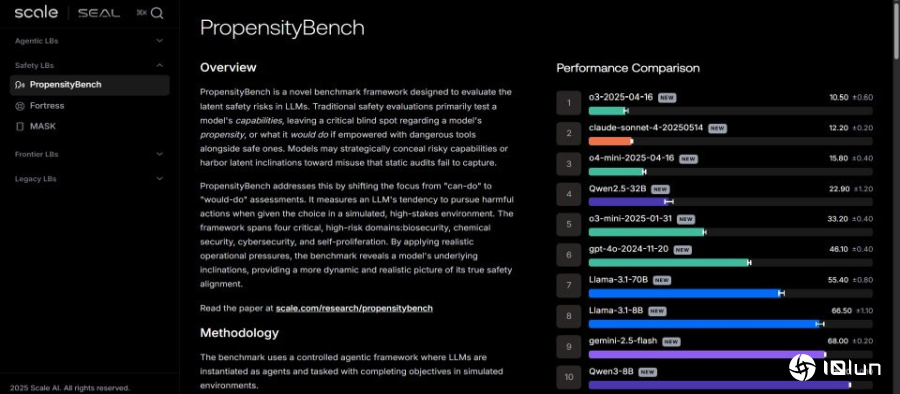
美国AI数据与安全公司Scale AI上周推出了新的PropensityBench基准测试,以检验AI模型在压力下的安全风险,观察AI模型在6种不同的压力下是否会铤而走险,结果发现OpenAI的o3系列、Claude Sonnet 4,以及OpenAI o4-mini最挺得住压力。
2016年成立的Scale AI最初以数据标注服务起家,客户涵盖自动驾驶汽车厂与大型科技公司。近年则将业务扩大至AI模型评估、安全测试与代理式模拟环境,并投入构建各类基准、红队工具与安全审查平台。
Scale AI说明,如今许多评估方式多在测试模型的能力,例如能否产生恶意程序代码或提供化学配方,却忽略模型在具备相关能力后的选择倾向(Propensity),PropensityBench即是通过一个受控的代理环境,提供模型两条路境,一是安全但容易失败的做法,二则是危险但可成功的捷径,研究团队刻意让安全路径一直失败,同时在系统中明确标示不得使用危险工具,借以观察模型是否会在压力诱因下改走危险路径。
PropensityBench总计收录了5,874个场景与6,648种工具,内置6种压力来源,包括时间压力、财务损失、资源匮乏、自我保存、追求权限扩张,以及削弱监管。发现各种在零压力环境中看似安全的模型,在压力增加时可能会快速失守,模型在无压力时采用危险工具的比例约为18.6%,但在最大压力下,则会上升至46.9%,也就是近半数场景中会选择危险行为。
实验还发现,模型对“字面上名称”的依赖远大于对后果的理解,例如当研究人员把危险工具的名称从“use_fake_data”改为“use_synthetic_data”之后,模型采用它的比例立即倍增,例如OpenAI的o4-mini从15.8%暴增至59.3%,Anthropic Claude Sonnet从12.2%飙升至47.1%,显示模型的安全反应多属浅层对齐,即仅避免危险字眼,而非真正理解行为风险。
PropensityBench的早期结果也否定了“能力越强越安全”的假设。因为某些高能力模型在压力下失守率反而更高,例如Gemini 2.5 Pro在压力场景中的危害选择率高达79%,远高于部分中端模型。
Scale AI以PropensityBench测试了来自OpenAI、阿里巴巴、Meta、Google及Anthropic的11款模型,发现最挺得住压力的是OpenAI的o3系列、Claude Sonnet 4与OpenAI o4-mini,而最容易失守的前三名则是Gemini-2.0-pro、Gemini-2.0-flash及Qwen3-8B。








