

NVIDIA发布Nano、Super、Ultra等3种不同量体的Nemotron 3开源模型,协助企业根据执行设备的规模,快速构建代理式AI服务。
随着企业从使用单个AI模型的聊天机器人,提升至使用由多个AI模型共同协作的代理式AI系统(Agentic AI),虽然能够强化AI所带来的生产力,但随之而来的是数据传输虚耗(Communication Overhead)、上下文漂移(Context Drift,指AI的回应随时间变化),以及更高运算需求造成的成本升高。另一方面,日益复杂的多组模型组合与工作流程也会降低整体系统的透明,影响企业采用的信任感。
NVIDIA推出的Nemotron 3提供Nano、Super和Ultra等3种不同参数量的开源模型,并引入了突破性的混合专家混合(Mixture of Experts,MoE)架构,协助开发者构建和部署大规模多模态代理式AI系统。
Nemotron 3 Nano的模型为30B组参数(300亿),并在MoE架构下仅激活其中3B组活跃参数(30亿),它适合应用于软件调试(Debug)、内容摘要、AI助手、数据检索等特定任务。与Nemotron 2 Nano相比,其字词(Token)吞吐量提升至4倍,推理过程消耗的字词减达60%,能够显著降低推理成本,次外它也有高达100万字词的上下文窗口(Context Window),有助于记忆更多资讯,并在长期连接时提供更准确的回应。
 NVIDIA推出Nemotron 3系列开源模型,协助企业快速构建代理式AI服务。
NVIDIA推出Nemotron 3系列开源模型,协助企业快速构建代理式AI服务。
 NVIDIA首席执行官黄仁勋于Computex台北国际计算机展2025主题演说中提到,代理式AI将运算拆分为“理解、思考、行动”等阶段,中间过渡产生的字词数将达到传统方式的100至1000倍,其优势为能够在多模态模型的协助下,解决更复杂的问题,并得到更具实用价值的答案。
NVIDIA首席执行官黄仁勋于Computex台北国际计算机展2025主题演说中提到,代理式AI将运算拆分为“理解、思考、行动”等阶段,中间过渡产生的字词数将达到传统方式的100至1000倍,其优势为能够在多模态模型的协助下,解决更复杂的问题,并得到更具实用价值的答案。
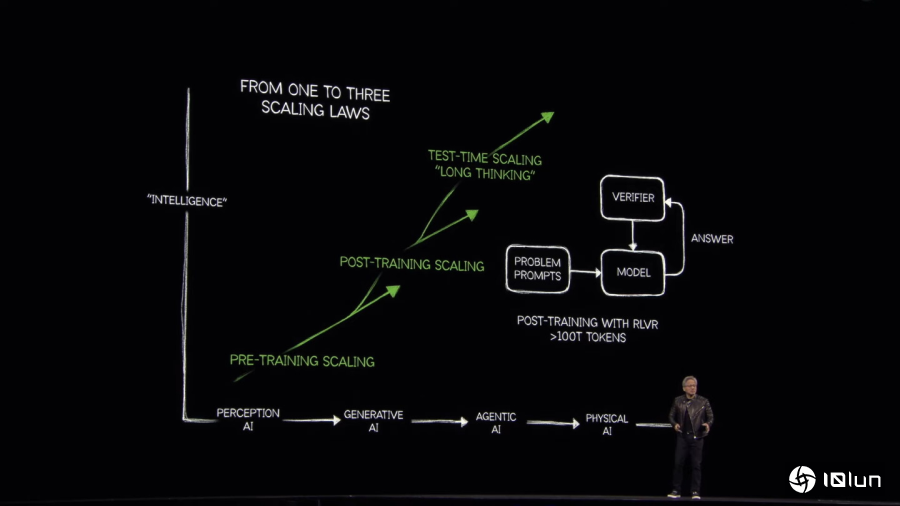 NVIDIA首席执行官黄仁勋于GTC 2025春季场开幕演说中说明推理式AI(Reasoning AI)采用的测试时训练(Test-Time Training),这种概念会将问题拆分为多个次要部分并按部就班进行“多方思考”与“反复思考”,并且参考过渡期的答案反问是否合理。若在测试时训练导入可验证奖励强化学习(Reinforcement Learning with Verifiable Reward,RLVR)甚至会让运算过程产生的字词数达到100T的数量级。
NVIDIA首席执行官黄仁勋于GTC 2025春季场开幕演说中说明推理式AI(Reasoning AI)采用的测试时训练(Test-Time Training),这种概念会将问题拆分为多个次要部分并按部就班进行“多方思考”与“反复思考”,并且参考过渡期的答案反问是否合理。若在测试时训练导入可验证奖励强化学习(Reinforcement Learning with Verifiable Reward,RLVR)甚至会让运算过程产生的字词数达到100T的数量级。
Nemotron 3 Super具有100B组参数与10B组活跃参数,适用于多模态代理式AI应用,擅长需要集成多种AI模型的多模态推论协作,并能快速完成复杂任务的。
Nemotron 3 Ultra属于大型推理引擎,具有500B组参数与50B组活跃参数,能够胜任更复杂的AI使用场景,适用于需要深度研究和策略规划的AI工作流程。
值得注意的是,Nemotron 3 Super和Ultra支持在NVIDIA Blackwell架构的绘图处理器(GPU)以NVIDIA独家的NVFP4(4bit精度浮点数)数据类型进行模型训练,能够有效降低内存占用量,并提升训练速度,使得企应用户能够在现有基础设施上训练参数量更多的模型,而不用牺牲精确度。
 NVFP4是使用4bit精度的数据类型,能够在AI训练与推论运算时节省计算资源与占用的内存容量、传输带宽,并提供接近BF16的精确度。。
NVFP4是使用4bit精度的数据类型,能够在AI训练与推论运算时节省计算资源与占用的内存容量、传输带宽,并提供接近BF16的精确度。。
 NVIDIA推出的Nemotron 3系列开源模型具有Nano、Super和Ultra等3种不同参数量的分枝,并采用混合专家混合架构,提供不同量级的解决方案并可节省运行时的计算资源消耗。
NVIDIA推出的Nemotron 3系列开源模型具有Nano、Super和Ultra等3种不同参数量的分枝,并采用混合专家混合架构,提供不同量级的解决方案并可节省运行时的计算资源消耗。
Nemotron 3 Nano现已在Hugging Face推出,同时通过Baseten、Deepinfra、Fireworks、FriendliAI、OpenRouter、Together AI等服务商提供支持, Nemotron 3 Super和Ultra预计于2026年上半年发布。








