OpenAI在ChatGPT Atlas的代理模式推出安全更新,替浏览器代理导入新的对抗式训练模型检查点,并强化周边防护机制。OpenAI表示,更新主因是通过内部自动化红队演练发现一类新的提示词注入攻击手法,因此先行修补,以降低代理在执行用户任务时被误导的风险。
所谓代理模式,是让系统在用户浏览器中读取网页内容并代为点击与输入,也可能在处理邮件、文件或行程表等工作流程中接触到大量外部内容。OpenAI提醒,当代理能在登录状态与既有工作脉络下采取动作,攻击者就可能把恶意指令混入邮件、附件、共享文件或一般网页,诱使代理把不受信任的文本误当成应遵循的指令,导致偏离用户原本的要求。
OpenAI内部自动化红队演练发现一类新的提示词注入攻击手法,以OpenAI示范场景来说,攻击者可先投放一封含恶意指令的邮件到收件箱,之后用户请代理撰写外出自动回复时,代理在查看未读信件的过程中遭到误导,反而发送辞职信给用户的主管或CEO,导致外出自动回复没有完成。也就是说,提示词注入攻击不必依赖传统网站漏洞,甚至不一定要通过钓鱼引导用户互动,也可能在日常工作流程中被触发。
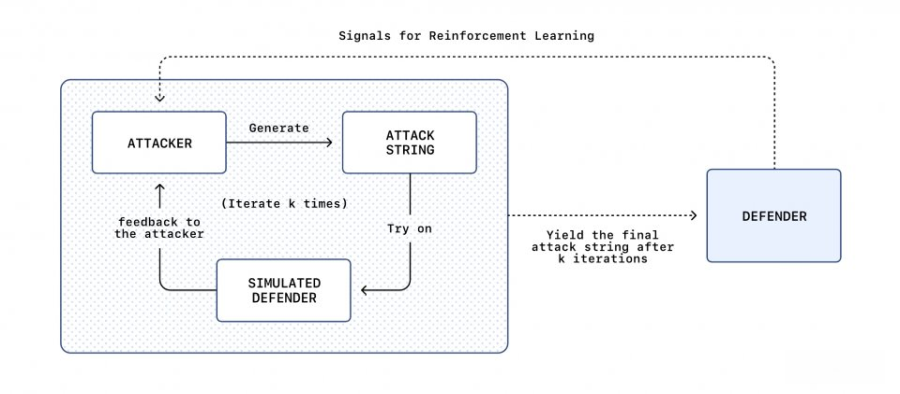
OpenAI表示已替Atlas浏览器代理推出安全更新,内容包含新一版经对抗式训练的模型检查点,并加强周边防护措施。OpenAI也说明其自动化红队做法是以大型语言模型为基础,通过强化学习训练自动攻击者,让其在模拟环境中反复试探不同的提示词注入策略,再利用目标代理的推理与动作轨迹作为反馈,快速找出可成功误导代理的方式。
当自动化红队发现新的有效攻击模式,防守端就把这些案例纳入对抗式训练,并把攻击轨迹用来改善模型以外的防护堆栈,例如监控机制、放入模型脉络的安全指示,以及系统层保护措施,让代理在接触不受信任内容时更能维持以用户意图为优先的判断,并在关键动作前要求确认。
针对用户端的风险管理,OpenAI建议在任务不需要登录时尽量以注销状态或未登录状态执行,并在系统要求确认寄信、购买等高影响动作时仔细核对内容。OpenAI同时提醒,交付任务时避免给出过于宽松的指令,改以更明确、范围更小的需求描述,可降低不受信任内容干扰代理判断的机会。








