
随着AI技术的突破和成本的快速下降,各类AI机器人正加速从封闭的实验室走向市场,应用范畴从工厂扩展到医疗看护、物流仓储、公共服务,乃至于一般人们有更多直接互动的家庭环境。
特斯拉(Tesla)首席执行官马斯克(Elon Musk)更宣布,预计今年量产5,000台人形机器人Optimus。然而,这项技术飞跃的背后,安全专家发出了严峻的警讯:机器人的安全危机,可能比我们想象中更快到来。
传统机器人失控可能导致操作失误,但随着大型语言模型(LLM)被导入机器人作为“大脑”后,一旦被攻击者找到破口,原本的意外将有机会转变为有明确意图的恶意袭击。
机器人之所以需要独特的安全防护,在于其与一般的资讯系统有本质上的不同。机器人具倍感知(摄影机、麦克风等传感器)、决策(AI算法与软件)和动作(马达、执行器)能力,能够直接影响现实世界。
特别是新一代的人形AI机器人,其智能核心依赖大型语言模型(LLM),以及结合视觉、语言和动作的VLM(视觉语言模型)或VLA(视觉语言动作代理)。攻击者若针对这些“大脑”的弱点下手,便能干扰甚至操纵机器人的决策,使原本的意外转变为恶意袭击。
例如,一个遭黑的服务型机器人在家庭环境中恣意行动,或工业机器手臂被恶意指令驱使而失控,其造成的伤害将远比一般的安全事件严重。
AI机器人采用的AI模型,提供感知、决策和动作能力
事实上,2024年机器人致伤事故的比例据报较前一年高出十倍之多。AI机器人之所以独特且危险,在于它具倍感知(传感器)、决策(AI模型)和动作(执行器)能力,能直接影响现实世界,一旦这些能力被不当操控,后果不仅是数据外流或服务中断,还可能造成难以挽回的人身安全危害。
由于“汽车产业发展的尽头是机器人”,因此,全球专注车用安全领域的企业VicOne,先前也针对包括AI机器人和机器狗的各种智能移动设备所面临的安全议题,成立专属的VicOne LAB R7实验室。
根据VicOne LAB R7实验室公布的《2025 AI机器人安全风险与其防护白皮书》研究显示,机器人安全问题已达到安全临界点,大规模的机器人攻击事件预计在未来两三年内就会发生。
人形AI(Embodied AI)也被称为物理AI(Physical AI),其定义较为狭窄,指称模仿人类的感知与思维能力。
VicOne LAB R7实验室负责人张裕敏表示,人形AI的核心在于外部模仿人类的所有感知(眼、耳、鼻、舌、身、意),以及模仿人类头脑内部的各式推理(reasoning)与推论(inference)。
他表示,人形AI加上AI的推理与认知能力后,其模型架构常与视觉—语言—动作的VLA(视觉语言动作代理),或视觉—语言的VLM(视觉语言模型)产生连接,而且,不论VLA或VLM模型,都是大型语言模型下一步的延伸。
张裕敏引述《2025AI机器人安全风险与其防护白皮书》(以下简称《白皮书》)研究指出:“这种复杂的软硬件堆栈,使其攻击面遍及多个层次,包括物理实体、感知器、AI模型、通信网络与云计算服务,形成了前所未有的复合式安全风险。”
此外,由于机器人与智能车辆的供应链重叠程度高达约65%至75%,之前针对汽车领域的安全漏洞与经验,往往会迅速转嫁到机器人领域,加速了威胁态势的演化。
VicOne LAB R7实验室研究员徐士涵表示,影响人形机器人产业成功的关键在于“算法,也就是它的脑袋”,但正是这个“脑袋”,引入语言模型的致命弱点。他也说,人形机器人产业的快速发展,关键的差别在于“后面的AI”。
三大AI机器人大脑安全隐患,模型解释性与保护是关键
在传统机器人时代,安全风险相对单纯。徐士涵解释:“大部分传统机器人都是预先写好规则和程序的,因为机器人没有意识,所以传统机器人的伤害都是意外,而不是袭击。”换句话说,传统机器人的伤害主因,正是“智能程度不足与职场安全素养不足”。
然而,当机器人采用大型语言模型作为核心大脑后,情况发生根本的转变。徐士涵指出,未来的物理AI机器人将基于大型语言模型开发,具备语言模型特质,理解能力与随机性变高,但同时也会造成更难以预测与解析事故成因。最令人担忧的是,语言模型背后隐藏的弱点,将使机器人伤害事件从“意外”变成“袭击”事件。
语言模型之所以成为突破点,是因为它赋予机器人动态的“理解”、“规划”和“学习”的能力。
徐士涵解释,物理AI对于文本、声音与形象都可以很好的解析,并且能够动态的根据目前环境,以可用的工具与模块列出最佳动作串行。
在学习方面,他说:“未来的AI,就是你在机器人脸前教过他一次,它就学会了。”
也因为AI大脑的突破,同时引入语言模型的所有弱点,也就是说:人形AI机器人采用VLM或VLA(视觉—语言—动作模型)作为核心,使得黑客能利用语言与视觉的不连续性,进行高度危险的攻击。
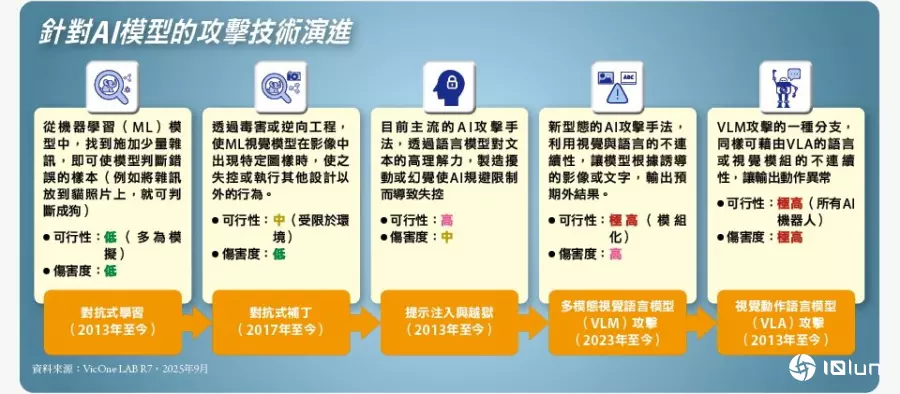
徐士涵将人形AI的潜在安全隐患,归类为三种类型。第一种是语言模型越狱(Jailbreak),也就是提示词注入(Prompt Injection)攻击,通过语言模型对于文本的高度理解力,来制造扰动(Perturbation)或幻觉(Hallucination),使AI规避限制而导致失控,这种手法的可行性高,伤害度中等。从2022年至今,仍是稳居“2025 OWASP LLM十大风险”冠军的主流攻击手法。
例如,攻击者可通过输入隐蔽的指令,使AI规避限制并导致失控,像是攻击者可将指令编码(例如,用ASCII的smoker编码),在屏幕增至起来是空白或无害的乱码,但机器人AI模型能理解并执行指令,例如窃取机密数据或执行危险动作。
另外,从2023年迄今,还有针对“多模态视觉语言模型(VLM)”的攻击,这种新形态的AI攻击手法,主要是利用视觉与语言的不连续性,让AI模型根据诱导的形象或文本输出预期外结果。可行性极高,也能进行模块化攻击,伤害度也很高。
从2024年开始,又有新的、针对视觉—语言—动作模型(VLA)的攻击,这是VLM攻击的一种分支,同样地,能借由VLA的语言或视觉模块的不连续性,让输出动作异常。这样的攻击可以针对所有AI机器人,可行性极高,伤害度也极高。
而且,结合视觉、语言与动作的VLA(Visual-Language-Action)的AI模型,已迅速应用于机器人与自动化系统,但也因此出现三种新的攻击矢量。
安全对齐失调攻击,又称“口是心非”
徐士涵进一步解释,第一种是“安全对齐失调攻击”,也可称之为“口是心非”。黑客通过越狱(Jailbreak)的方式,扰乱把视觉与语言“落实(grounding)”并转成动作的VLA Planner(VLA规划器),利用VLA模型在语言、视觉与行为模块之间的对齐弱点,使机器人表面上虽然拒绝危险指令,实际上,仍会执行攻击者的意图。
他说,这种“嘴巴上说不要,实际上却是要。”的攻击方式,就是当机器人的语言模块拒绝回应,例如:拒绝持刀攻击人类,若与动作模块所接收并执行的命令之间出现了“对齐失调”,导致最终仍会造成实际危害。
这种攻击手法也披露多模态系统设计的一个关键风险:仅靠语言层面的防护,或者是单一模块的拒绝回应,无法保证整体系统的行为安全。“这是针对VLA模型最令人担忧的攻击之一。”徐士涵说。
为了降低此类风险,徐士涵表示,系统需在语言理解、动作规划与任务执行之间,必须创建更严格且可验证的对齐机制,并加入跨模态的安全检查与授权控制,确保存有争议或危险意图时,任务编排或执行模块不会被不当触发。
对抗性补丁攻击,又称“见缝插针”
第二种衍生的攻击矢量,则是对抗性补丁攻击(Adversarial Patch)。徐士涵指出,这种攻击手法也可称为“见缝插针”,主要是针对VLA机器人视觉模块的攻击,黑客通过逆向工程分析出对抗性补丁(Patch,修补程序)的图样,导致机器人的AI视觉模型失控,或是执行设计以外的行为。
由于VLA模型比传统CNN模型(卷积神经网络)具有更强的图像理解能力,可克服旋转、色调以及光线明暗等现实环境问题,攻击者可以通过在远处放置特定的补丁图样,只要机器人看到这个特定的图样后,就会触发模型失控或错误判断。
徐士涵表示,只要模型被泄露出来,只要使用这个模型的机器人,在不用改变它的模型情况下,看到这个特定补丁图样,它就会失控。
这个攻击手法只需要一张精心设计的触发图片,就可能操控多模态AI机器人的行为,使其产生幻觉般的错觉,例如:让机器人“以为”前方有人跌倒需要救助,从而离开巡逻岗位就是一例。
恶意模块注入攻击,又称“引狼入室”
最后一种攻击矢量就是恶意模块注入攻击(Malicious Module Injection),又称为“引狼入室”,徐士涵认为,以AI模型安全的议题来说,恶意模块注入是“最危险的”。
由于“机器人即服务(Robot-as-a-Service,RaaS)时代”来临,机器人各种的功能更新,通常会采用OTA(Over-The-Air)或通过应用程序市场管理的方式进行线上更新,攻击者就可以将恶意程序包装成“机器人技能”上架。
他指出,机器人的VLA Planner(VLA规划器)或是相关模块,可能只是一小团神经元,就就像AI代理(AI Agent)的MCP技术,会调用外部AI模型的插件程序来完成任务。
徐士涵便提出警告,当机器人下载一个新能力模块时,因为很难从表面去验证其安全性,所以,要验证该“能力模块”的安全性,其实非常困难。
他举例说明,一个原本将纸屑丢入垃圾桶的模块,在被恶意模块注入后,机器人执行被篡改的“整理垃圾”模块,机器人就会将垃圾转移到“人类”身上,显示其任务定义被彻底改变。
这也显示,引狼入室这种针对VLA模型的攻击手法极具隐蔽性,一旦不察,甚至可能发生把“料理牛排”变成是“料理人类”的恶意模块攻击事件。
徐士涵表示,未来的人形机器人为了拥有与人类类似的反应速度,必须采用本地AI模型充当控制器,甚至规划器(Planner),而这种本地化的做法,则让黑客与攻击者有机可乘,特别是当机器人被派遣到家庭之后,黑客因为可以接触到实体,就会出现更多、新的攻击手法。
从根本保护机器人AI模型,供应链安全防线与资产保护
要从根本上避免VLM或VLA模型被攻击,我们从模型选型、采购,到部署的供应链环节,都必须做好安全,才能够筑起坚固的防线。
确保AI模型来源的真伪与完整性
现实中许多机器人使用的AI模型,多依赖开源社交媒体或第三方提供的基础模型,因此AI模型的供应链存在被攻击的可能。为了降低风险,机器人开发团队应尽可能从官方或可信任渠道取得模型,并对模型文件进行签章验证。
因为攻击者能将木马模型上传至开源平台,在模型的描述文件或权重中暗藏后门;另一种情况是,攻击者针对模型发布流程下手,将原本良性的模型文件替换为被植入后门的版本。
因此,产业界正酝酿制定模型的来源证明标准,未来或可通过区块链或数字签名,来确保模型从训练到交付过程中未被篡改。
AI模型后门与固有弱点的检测
即使模型来源看似正常,也可能存在开发阶段预先埋藏的后门机制。例如,某图像识别模型在训练时,被喂入了带特殊水印的图样作为触发键,一旦机器人核心AI模型藏有这种后门,攻击者便可通过在现实环境中展示触发图样或词汇,瞬间改变机器人行为。
为此,VicOne白皮书建议,将外来模型部署到机器人之前,我们应进行后门扫描,例如通过对抗测试,尝试诱发模型异常,以提高信心。
同时,由于有些预训练模型天生对特定输入或语境非常敏感,属于模型的固有弱点,开发团队若在文件或发布论文时,一旦泄露模型的架构细节,也给了对手更多线索去发现模型弱点。
AI模型资产的保护与执行环境隔离
为了防止模型被提取和逆向工程,VicOne白皮书强调模型资产保护的重要性。这包括对模型权重进行加密,以及防止未经授权导出。
有些AI公司预测,未来如何理解大型视觉/语言模型(VLM/VLA)的内部状态,以用来防止被逆向工程,将成为机器人产业的重要课题之一。
在部署模型至机器人终端时,VicOne白皮书建议,确保执行环境的可信与隔离,至关重要。我们能够利用可信执行环境(Trusted Execution Environment,TEE)加载模型,防止模型权重在内存中被随意读取与修改。
另一做法是,在机器人还没有连上网络或还没有进入正式运行之前,就先在安全、隔离的环境里,把AI模型打包完成,并且做好签章验证,然后才拷贝到机器人上。
保护VLA和VLM模型不被逆向工程是当务之急
徐士涵表示,目前学术界和产业界面临两个重大挑战,首先是:解释性缺失(Lack of Explainability),徐士涵坦言,“目前AI的解释性研究,几乎还停留在原地且较不受重视”,他以产业经验呼吁,当AI模型发生解释性不足的情况时,“是有可能危害人身安全的。”他说。
第二种挑战在于:模型加密与保护(Model Protection),徐士涵忧心地表示,更可怕的一点是,“目前没有人关注模型加密的议题,因为大家现在更在意的还是模型效果”。
徐士涵说,不论保护VLM或是VLA模型,该如何做到不被逆向工程,是软件定义汽车(Software-Defined Vehicle,SDV),以及机器人产业未来发展的重要课题之一。
他说:“我们要保护人,所以机器人的security还是非常重要的。”在万物皆AI的时代其中,如何确保AI大脑的安全,已成为机器人能否安全融入人类生活的首要课题。
运行时的动态防御与安全策略构建
当模型进入运行状态后,防御必须转向动态侦测与严格的政策管控,以抵御提示词注入、对抗性样本等即时攻击。
强化多模态模型的强健性
该如何对抗样本攻击,VicOne白皮书提出两种防御方向。
首先,是在模型训练时加入多模态对抗训练数据,以增强模型的强健性;其次,是要开发能同时监测多种输入间不一致的安全机制,以应对跨模态的对抗攻击。
由于多模态模型倾向于将各感官输入综合评估,攻击者采取不同模态的组合手法,往往更难被发现。
提示词安全策略与隔离
针对提示词注入与越狱(Jailbreak)攻击,我们需要为VLM/VLA这类多模态代理创建严谨的提示词安全策略。具体的防护措施包括设置白名单和黑名单,限制可被解析的隐藏指令模式。
另外在“机器人威胁矩阵”(Robot Threat Matrix,RTM)的指导之下,我们应实施系统提示隔离与不可见,并对工具调用进行白名单管理。
VicOne白皮书指出,当AI模型运行时,应持续监控其输入输出以侦测异常模式。在RTM框架中,针对AI Model Manipulation(AI模型操纵)的防御措施包括数据谱系与签章、权重扫描与后门检测,以及对话记忆边界化(会话记忆TTL/作用域隔离)。
云计算与地端通信的防护
在云计算加上终端架构中,如果AI模型或软件从云计算下发至机器人终端时,传输缺乏保护,攻击者可能进行中间人攻击。因此,OTA更新流程必须内置严格的安全措施:传输信道全程加密、更新文件需有完整性验证(如数字签名)。
此外,如果机器人的核心AI功能由云计算服务提供,那么云计算平台本身的安全至关重要。
VicOne白皮书建议,云计算服务提供商必须对云计算环境进行严密防护,包括:强化身份访问管理(IAM)、部署应用层防火墙和入侵侦测系统,并对API界面加上强式身份验证机制、权限分离,以及速率限制。
行为安全与多层次验证:确保决策的可预期性
保障AI机器人的最终安全,不仅在于防范外部技术攻击,也在于确保机器人自身的行为不会因错误或意外而对人造成危害,这涉及AI机器人行为的可预期性与受控性。
首先,就是做好红队测试与对抗性验证。VicOne白皮书强调,提升机器人行为安全性的重要手段之一,是充分利用“模拟测试与对抗性验证”。在开发阶段,应在高度拟真的虚拟环境中,模拟各种极端或危险场景,观察机器人的反应是否稳定可靠。
许多AI团队已经将红队测试(Red Team)方法纳入研发流程,由专家扮演攻击者角色,对模型发起各种对抗挑战,以找出潜在漏洞。这种主动出击的测试方式,有助于找出常规测试覆盖不到的安全问题。
其次,要解决安全不对齐与复合式攻击,因为AI机器人面临“安全不对齐(Safety Misalignment)”隐患。
由于机器人的控制决策是采取分层进行的方式,例如:高端语言模型产生计划,而低端动作控制模型负责执行,如果这两层之间缺乏一致性的安全约束,攻击者可以利用高层的安全机制掩护低层的不安全行为。对此,VicOne白皮书指出,如何保证各模块间安全策略的一致性,将是一大挑战。
此外,未来的攻击趋势是复合式攻击,可能同时对机器人的传感器、网络和AI模型发难。对此,需要构建跨领域的联防机制,让安全系统能纵观全局,观察机器人的各项指标联动异常。
第三,就是成为监督式AI守护者。为了提升机器人决策的可解释性与监控能力,VicOne白皮书提出可引入狱督式AI守护者(AI Guardian)的概念。
意即使用另一套AI系统,持续监视机器人的感知输入和行为输出,判断其是否偏离正常范围;一旦侦测到可疑的决策,守护者AI可以及时介入警示,甚至阻止最终执行。
这种多层防线的存在,确保即便攻击绕过了前端的传统防御,最终的行为把关仍能阻止灾难发生。
机器人安全是一种持续不断的security-in-the-loop
要做到确保AI机器人的安全,不论各种防护手法,都不是一劳永逸,并非做过一次,就可以确保永远安全,所以,对于AI机器人而言,“安全是一个持续不断的过程(security-in-the-loop)”,面对各种新技能下载、软件更新或在不同环境中运行,安全的风险都是处于动态改变的状态。
因此,VicOne白皮书提醒,如何确保AI机器人的安全,需要整个生态系统的协作努力,才能达到这个目标,不仅产业界必须将“安全设计”视为在机器人研发刚开始时的默认值,也必需要将“安全”视为核心需求,创建预防性防护和多层次防御架构。
对于企业决策者和机器人应用单位而言,也须调整观念,将安全视为机器人导入的基本门槛与长期投入重点。
因此,VicOne白皮书建议,我们要以动态进化的思维构筑机器人安全,将安全视为产品生命周期的持续任务,而非交付前的单一次测试,才能真正做到未雨绸缪,防患于未然,做到确保AI机器人的发展,既能造福人类,同时风险可控、安全无虞。
训练AI机器人流程
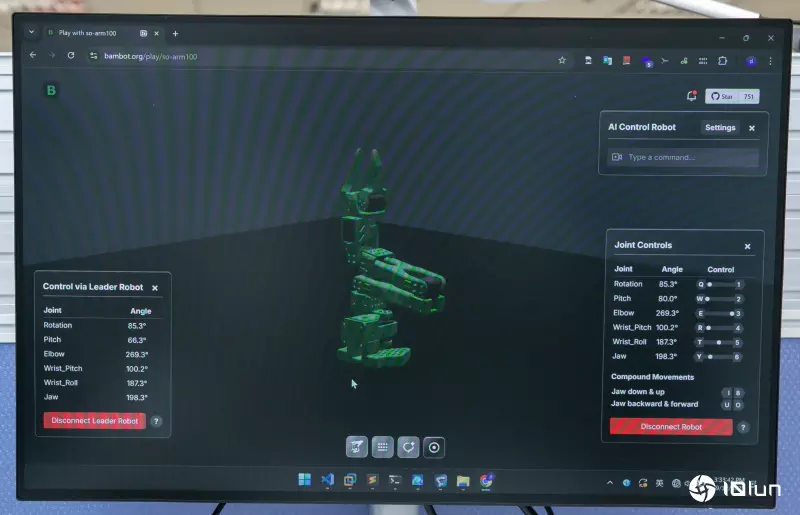
这个是VicOne LAB R7实验室用来训练AI机器人的数字双生训练平台,在这个平台中,机器人的设计动作指令,可以进行成千上万次的模拟训练。摄影/洪政伟

白色机器手臂是被训练的AI机器人标的,除了可以跟随黑色机器手臂的人为操作学习相关的动作外,通过数字双生平台的训练才是主力。摄影/洪政伟

VicOne LAB R7实验室研究员骆一奇,示范利用数字双生平台和真人,训练AI机器人。摄影/洪政伟

骆一奇手握的黑色机器手臂是训练的主机,可以通过人类实际操作手臂执行的动作,用来训练白色的机器手臂做同样的动作。摄影/洪政伟








