
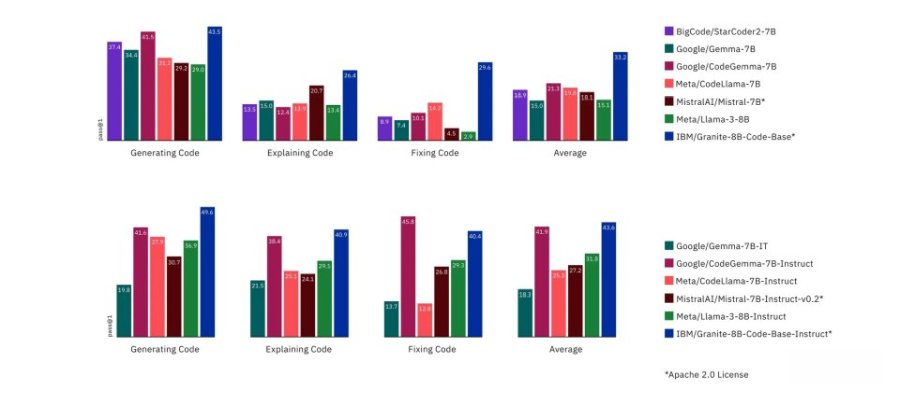
IBM以Apache 2.0授权条款开源一系列Granite程序代码模型,大小从30亿到340亿参数,包括基础模型和指令跟随模型,可用于应用程序现代化任务,甚至也可在内存有限的设备上运行。经多个基准测试实验,Granite程序代码模型在包括程序代码生成、修复与解释任务,较多数开源程序代码大型语言模型的表现更好。
Granite程序代码模型具有多个变体,而IBM提到,针对大部分企业使用案例,80亿参数的Granite程序代码模型,是权重、执行成本和功能最合适的组合。同时Granite程序代码模型也有高达340亿参数的变体,而IBM使用一种称为深度放大(Depth Upscaling)的方式,来训练这些较大型的模型。
深度放大是一种增加模型层数的方法,以340亿参数的Granite程序代码模型来说,研究人员创建了两个200亿参数的模型变体,每个变体有52层,借由将第一个变体的最后8层,以及第二个变体的前8层去掉,再将这两个模型整合,形成一个88层、具340亿参数的新模型。研究人员提到,该方法将使模型层数更深,以提高其性能。
官方同时也发布了Granite程序代码指令跟随模型,该模型经过Git提交和人工综合指令,还有开源合成程序代码指令数据集微调。
研究人员针对当前各种Apache 2.0授权的开源模型,以HumanEvalPack、HumanEvalPlus和RepoBench基准测试进行比较。Granite程序代码系列模型在Python、JavaScript、Java、Go、C++和Rust程序语言的程序代码合成,修复、解释、编辑和翻译都表现良好。

图片来源/IBM
虽有部分模型在生成和修复程序代码等任务超越Granite程序代码模型,但整体来说,Granite程序代码模型能力表现平均,在多项测试中都获得第一的位置。开发者现在已经可以在Hugging Face、GitHub、watsonx.ai和RHEL AI平台使用到Granite程序代码系列模型。







