
随着2025年OCP高峰会(2025 OCP Global Summit)来到第二日,身为OCP重要厂商的博通也发布主题演讲,以“人工智能扩展的网络架构”(Networking for AI Scaling)为题,强调以太网(Ethernet)的重要性,表示除了用于水平扩展(Scale-Out),在垂直扩展(Scale-Up)上也是不二选择。
谈到以太网的优势,博通资深副总裁暨核心交换机业务群总经理Ram Velaga指出,它具有开放性(open)、互通性(interoperable)、可组合性(composable)的生态系与技术基础,因为没有专有技术束缚,可以让各企业按自身合适的方式进行设计。

近期有家公司宣布三项数据中心计划,相信很多人都疑惑,为何要盖这么多数据中心、投入这么多电力?Velaga指出,原因是机器学习和人工智能的本质就是一种“分布式运算系统”(Distributed computing system),没有一颗XPU的规模足以单独处理所需的工作负载,必须将多个XPU连接、协作,这正是“网络”发挥关键作用之处,而“网络”就是“计算机”(The network is the computer.)。

由于以太网开放、具韧性且经济实惠,不管是Scale-Up、Scale-Out还是Scale-Across(跨数据中心扩展),以太网都是能同时覆盖这三个层面的网络技术。
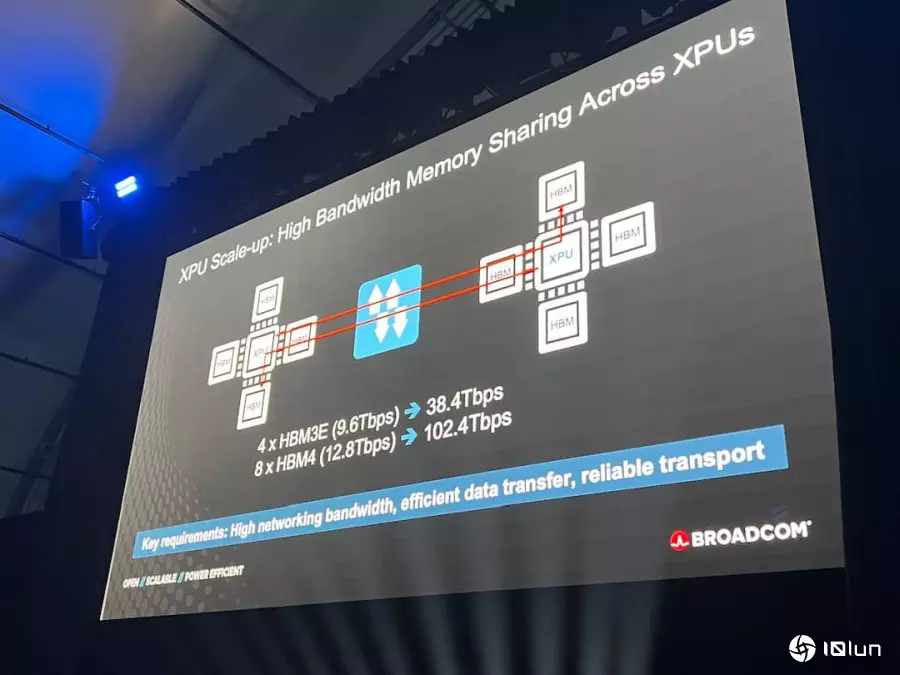
Scale-Up是什么?为何以太网适合Scale-Up?Scale-Up是确保当有多颗XPU时,其中一颗XPU上的HBM能被其他XPU访问。每一颗XPU与其连接的HBM之间的带宽大约是40Tb/s,因为通常搭载4颗HBM、每颗速度约9.6Tb/s;未来每颗XPU拥有8颗HBM,每颗约达12.8Tb/s,总带宽可达100Tb/s。Velaga解释,当两颗XPU要互通数据时,网络传输时就需要非常高的带宽,这正是Scale-Up最关键的要素之一,目前已经有ESUN(Ethernet for Scale-Up Networking)联盟,相信以太网的开放性会在这部分带来很大的差异。
随着越来越多家公司需要采购XPU,若仅依赖单一供应商,将面临垄断状况,因此需要异质生态系,让不同公司开发自家XPU,各自拥有工程团队、专利创新,才能持续推动技术发展。
Velaga表示,非以太网技术会试图定义XPU内部如何运行与连接,而以太网则是在设计上有明确分界,即“XPU运行与网络层运行分离(decouple)”,一边是XPU内部运行,一边是以太网的网络层处理。

如此一来,各家公司可自由发挥创新,按自身合适方式进行扩展,思考如何调度流量(traffic scheduling)、处理内存语义(memory semantics)以及设计上层软件层。在这些设计下,底层的以太网则维持简单与标准化,一切基于现有标准和既有规范,没有“专有”(proprietary) 的东西。目前许多公司也有共识,决定携手合作,推动以太网成为Scale-Up网络的核心技术。
 博通推业界首款800G AI以太网络NIC
博通推业界首款800G AI以太网络NIC除了芯片与硬件外,软件支持也是以太网Scale-Up相当重要的一环。Velaga指出,OCP已成立一个工作小组,确保修于以太网Scale-Up的软件能开发和使用。这套软件是SONiC的一个版本。

至于成本方面,相比建造十万颗GPU集群的成本至少要30亿美元,构建同等规模的以太网络,成本可能低于一亿美元(不含缆线与网络适配器NIC)。而当以太网络交换机的带宽提升至100 Tb/s时,反而能使网络层级精简,能降低网络拥塞、减少光模块和交换机数量、降低整体网络延迟,进而大幅缩短任务完成时间。
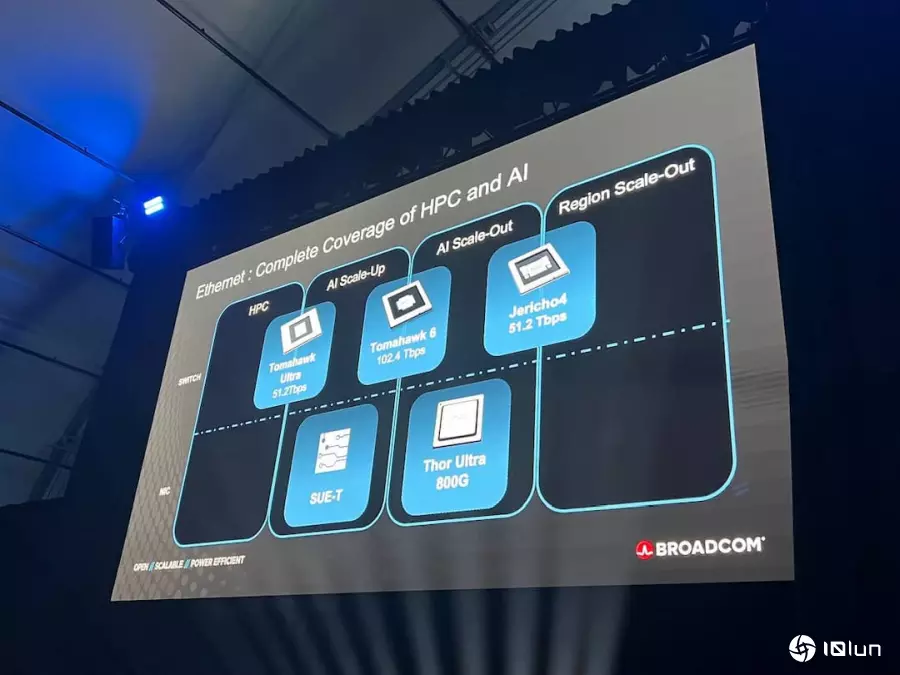
针对以太网是否低延迟,Velaga则表示以太网能构建全球最低延迟的互联网络,且可突破实体机柜与铜线长度的限制,能横跨多排机柜、甚至跨数据中心运行的网络技术,其中一个关键是不断提升以太网交换机的带宽能力,也因此,博通力拼平均每18-24个月交换机带宽倍增。

目前博通已经进入第三代CPO技术,其交换机平台不仅支持自家CPO,也支持合作伙伴(如NTT)开发的共封装光学模块。同时,博通也在这次OCP高峰会中发布“Tor Ultra”芯片,是业界首款真正的800Gb NIC产品。

该产品支持两种不同的外形规格,无论8x100G还是4x200G,都符合Ultra Ethernet标准,并专注于强化RDMA(远程直接内存访问)技术,包含多封装传输(Multi-packing)、乱序数据放置(Out-of-order placement)、选择性重试(Selective retries)等特性,都是构建数十万GPU集群以实现RDMA扩展规模所必须的要素。而这款产品能够连接到任何品牌的以太网交换机、使用任何品牌的缆线,或者搭配任何XPU,性能都不会受影响。
(首图来源:科技新报)








