OpenAI于稍先前推出新一代语音模型,通过API向全球开发者开放。此套模型包括语音转文本及文本转语音功能,提升语音代理的性能及应用范围。新模型在语音识别准确度及可靠性上超越现有基准,特别适用于客户服务及会议记录等场景,另外这次也开放新功能,首次允许开发者自定义语音风格。
OpenAI最新推出的gpt-4o-transcribe及gpt-4o-mini-transcribe模型,在语音转文本方面显著提升表现。根据多项基准测试,如FLEURS,其词错率 (Word Error Rate, WER) 较原有的Whisper模型大幅下降,展现更佳的语言识别能力。这些模型针对口音、嘈杂环境及语速变化等挑战改善,适用于客服中心及会议笔记转录等场景。
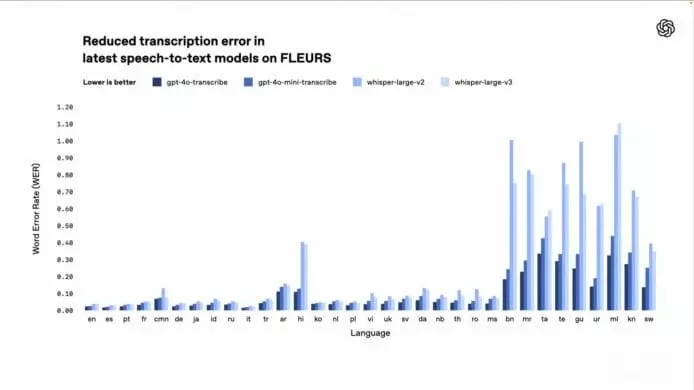
新模型识别准确率更高
新推出的gpt-4o-mini-tts文本转语音模型,首次允许开发者指定语音表达方式,例如模仿“具有同理心的客服人员”。此功能打开了从动态客服到创意故事讲述等多样化应用。据悉这种可控性让开发者能创造更具个性化的语音体验,惟目前仅限默认人工声音,以确保安全。
OpenAI计划持续提升语音模型的智慧及准确性,并探索让开发者引入自定义声音的可能性,同时关注安全标准。此外公司正研究视频等多模态技术,以实现更全面的代理体验。
数据源:OpenAI、OpenAI@YouTube








