
微软研究人员试图弄清楚如何将更多功能塞进规模较小的模型,他们最终找出一种创新的训练方法,灵感竟然来自儿童读物,新模型Phi-3系列因此诞生。
相较于GPT-4等大型语言模型(large language model,LLM),微软新发布的Phi-3-mini(38亿参数)以更小的数据集进行训练,具4K token和128K token两种上下文长度,目前已在Microsoft Azure、Hugging Face、Ollama上对外提供。微软还计划未来几周内推出Phi-3-small(70亿参数)和Phi-3-medium(140亿参数)两种版本。
微软AI平台公司副总裁Eric Boyd告诉国外媒体The Verge,Phi-3-mini功能与GPT-3.5一样,“只是规模更小”,他强调。
研究人员通过所谓“课程”对Phi-3进行训练,他们的灵感来自于孩子们如何从睡前故事、用字更简单的书籍或者谈论更大主题的句子结构加以学习。
Eric Boyd补充说,Phi-3是创建在先前模型迭代所学到的知识上。相较Phi-1专注编辑程序,Phi-2开始学习推论,到了Phi-3更加擅长编辑程序和推论。虽然Phi-3系列了解一些常识,但在广度上无法击败GPT-4或其他大型语言模型。
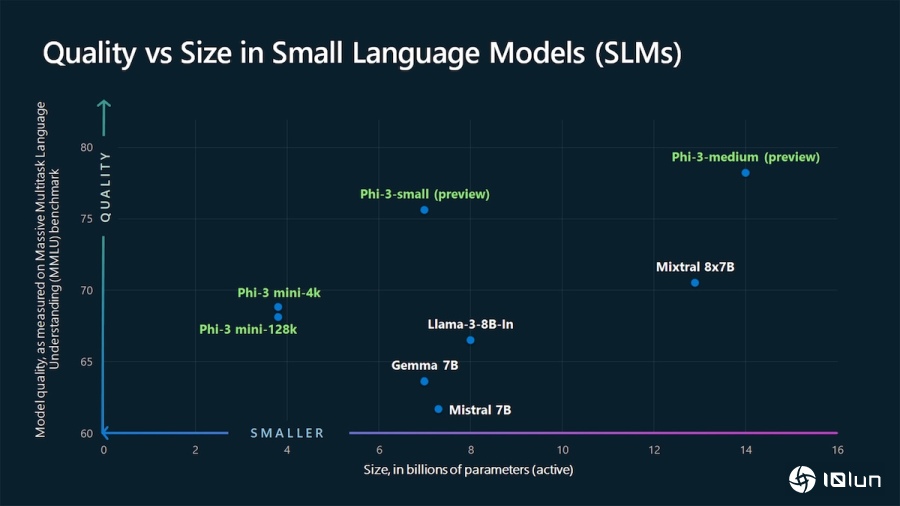
微软Phi-3与其他类似规模的模型进行比较。(Source:微软)
与大型语言模型相比,小型语言模型(small language model,SLM)通常成本更低,在手机和笔记本等个人设备上表现更好。另一媒体《The Information》稍早曾报道,微软创建一支专注于轻量级AI模型的团队;不只Phi系列,微软还开发一个专门解决数学问题的Orca-Math模型。
微软的竞争对手同样自行研发小型语言模型,大多数针对简单的任务,例如文件摘要或作为编辑程序代码的辅助功能。其中,Google开源的Gemma 2B(20亿参数)和Gemma 7B(70亿参数)适合简单的聊天机器人和语言相关服务。Anthropic的Claude 3 Haiku可阅读带有图表的研究论文并快速摘要内容,而Meta新发布的Llama 3 8B(80亿参数)可辅助聊天机器人和编码的功能。
(首图来源:shutterstock)








