
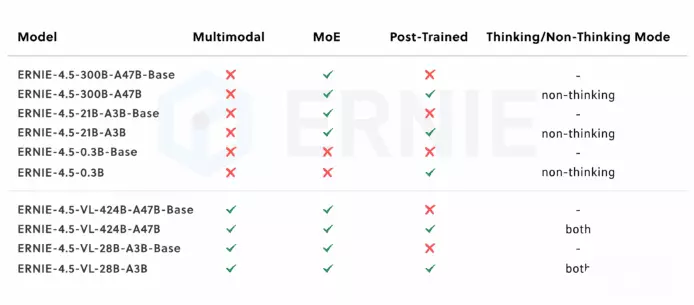
AI模型开源化已成趋势,百度最近就终于正式开源文心4.5系列模型,一次推出10款模型,涵盖47B、3B参数的混合专家(MoE)模型,以及0.3B参数的稠密型模型。

文心4.5开源系列针对MoE架构提出创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间。该架构适用于从大语言模型向多模态模型的持续预训练范式,在保持甚至提升文本任务性能的基础上,显著增强多模态理解能力。
模型通过在文本和视觉两种模态上进行联合训练,更好地捕捉多模态资讯中的细微差别,提升在文本生成、图像理解以及多模态推理等任务中的表现。结合多维旋转位置编码,并在损失函数计算时增强不同专家间的正交性。
推理方面,百度提出多专家并行协同量化方法和卷积编码量划算法,实现效果接近无损的4-bit量化和2-bit量化。动态角色转换的预填充、解码分离部署技术可更充分地利用资源,提升MoE模型的推理性能。
实验结果显示,文心4.5系列模型在多个文本和多模态基准测试中达到SOTA水准,在指令遵循、世界知识记忆、视觉理解和多模态推理任务上效果尤为突出。
在文本模型方面,文心4.5开源系列基础能力强、事实准确性高、指令遵循能力强、推理和编程能力出色,在多个主流基准评测中超越DeepSeek-V3、Qwen3等模型。在多模态模型方面,该系列拥有卓越的视觉感知能力,同时精通丰富视觉常识,并实现思考与非思考统一,在多模态大模型评测中优于闭源的OpenAI o1。
在轻量模型上,文心4.5-21B-A3B-Base文本模型效果与同量级的Qwen3相当,文心4.5-VL-28B-A3B多模态模型是目前同量级最好的多模态开源模型,甚至与更大参数模型Qwen2.5-VL-32B不相上下。
百度预告将联合Hugging Face等30+ 开源社区推出20节“文心飞桨・开源系列公开课”,携手产业导师与高校名师打造“文心名师系列・公开课”,并在北京、上海、深圳等10余个城市启动“文心开源服务站”。
来源:百度








