
AMD宣布将通过AMD Software: Adrenalin Edition 25.8.1版驱动程序,让搭载Ryzen AI Max+ 395处理器并配备128GB内存计算功能执行约与ChatGPT 3.0相当的128B参数的大型语言模型。
由于大型语言模型(LLM)的参数量会影响执行时占用的显示内存,可能会超过个人计算机显卡的容量上限,因此往往需要依赖云计算服务。AMD推出的Ryzen AI Max+ 395处理器集成如今最强的内置显示芯片,具有40组RNDA 3.5绘图架构运算单元,并可在系统安装128 GB主内存时,切割其中96 GB作为专属显示内存使用,并搭配16 GB共享内存,带来执行参数量更庞大模型的可能性。
AMD宣布AMD Software: Adrenalin Edition 25.8.1版驱动程序,将可让搭载Ryzen AI Max+ 395处理器与128 GB主内存的计算机在本地执行参数量高达128B的大型语言模型,并支持具备完整视觉功能与模型上下文协议(Model Context Protocol,以下简称MCP)的Meta Llama 4 Scout 109B模型。
其中关键就是AMD可变显示内存技术(Variable Graphics Memory,VGM),最高能切割容量高达96 GB的连续专用显示内存给予内置显示芯片,如此一来能够在没有安装独立显卡的前提下,于本地端执行FP4数据类型的128B参数模型,或FP16数据类型的32B参数模型。
读者可以下载最新版LM Studio以及AMD Software: Adrenalin Edition预览版(或更新版本)尝试这些功能。
文件下载
LM Studio:https://lmstudio.ai/
AMD Software: Adrenalin Edition 25.10 RC 24预览版:https://www.amd.com/en/resources/support-articles/release-notes/RN-RAD-WIN-25-10-RC-24-RYZEN-AI-MAX-395-VULKAN-LLAMA.html
 AMD通过驱动程序更新让Ryzen AI Max+ 395处理器支持于本地执行128B参数大型语言模型。
AMD通过驱动程序更新让Ryzen AI Max+ 395处理器支持于本地执行128B参数大型语言模型。
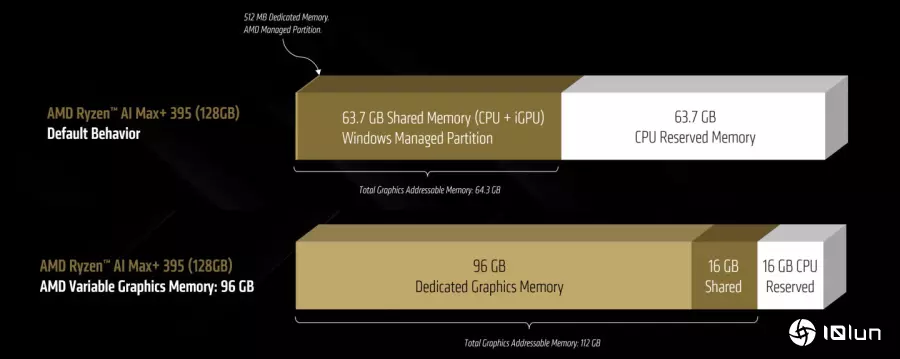 AMD可变显示内存技术(图中下半部)能分割96 GB作为专属显示内存,以及16 GB作为共享内存,让内置显示芯片最高能访问112 GB显示内存。
AMD可变显示内存技术(图中下半部)能分割96 GB作为专属显示内存,以及16 GB作为共享内存,让内置显示芯片最高能访问112 GB显示内存。
 我们先前介绍过的Asus ROG Flow Z13与HP ZBook Ultra G1a,以及Framework Desktop都搭载Ryzen AI Max+ 395处理器。
我们先前介绍过的Asus ROG Flow Z13与HP ZBook Ultra G1a,以及Framework Desktop都搭载Ryzen AI Max+ 395处理器。
支持Llama 4 Scout MoE
在可变显示内存技术加持下,搭载Ryzen AI Max+ 395处理器与128 GB主内存的计算功能够执行参数量更庞大的大型语言模型,甚至能够通过MCP与其他应用程序沟通,达到自动通过浏览器查询数据,或是阅读、搜索用户私有文件、数据库中的资讯,进一步提升代理式AI(Agentic AI)功能的完整性与丰富度。
AMD也进一步说明,Llama 4 Scout属于混合专家模型(Mixture-of-Experts,MoE),它整体具有109B参数量,运行时可以仅启动其中的17B参数(但完整的109B参数仍需存储于显示内存中),有助于提高AI推论运算性能,让系统达到每秒15组字词(Token)的输出速度。
另一方面,原本LM Studio的默认上下文窗口为4,096字词,如今在搭配Ryzen AI Max+ 395处理器与128 GB主内存的情况下,执行Llama 4 Scout时能扩张至256,000字词,大幅提高推理式AI与代理式AI的功能性。
 Ryzen AI Max+ 395处理器搭配128 GB主内存能让系统支持多种不同参数量以及数据类型的大型语言模型。
Ryzen AI Max+ 395处理器搭配128 GB主内存能让系统支持多种不同参数量以及数据类型的大型语言模型。
 Ryzen AI Max+ 395是第1款能够在轻薄个人计算机执行Llama 4 Scout的处理器。
Ryzen AI Max+ 395是第1款能够在轻薄个人计算机执行Llama 4 Scout的处理器。
 执行Mistral Large 123B与Llama 4 Scout 109B(启动17B参数)模型分别需要68 GB与66 GB显示内存。
执行Mistral Large 123B与Llama 4 Scout 109B(启动17B参数)模型分别需要68 GB与66 GB显示内存。
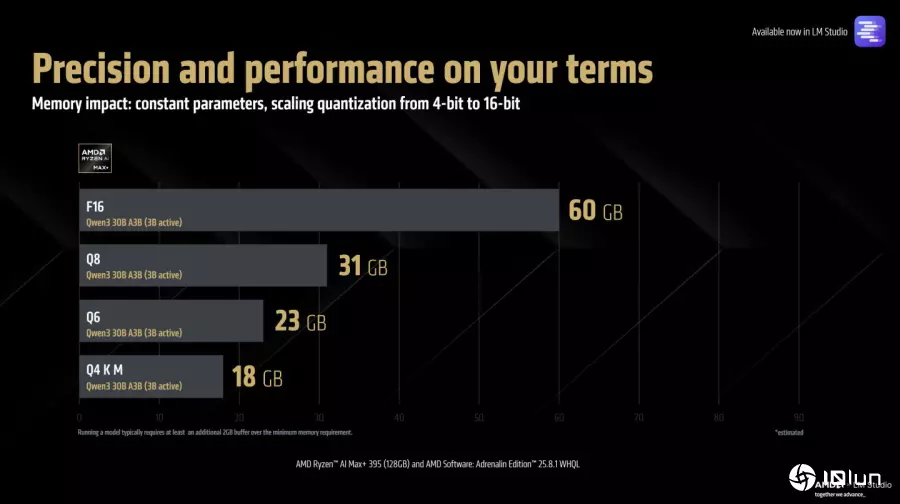 以Qwen 30B A3B模型为例,FP16数据类型与Q8、Q6、Q4 K M等不同数据量化格式所占用的显示内存对照表。
以Qwen 30B A3B模型为例,FP16数据类型与Q8、Q6、Q4 K M等不同数据量化格式所占用的显示内存对照表。
 如果将Llama 4 Scout 109B模型(启动17B参数)搭配Q4 K M数据类型的上下文窗口设置为256,000字词,占用的显示内存容量将高达92GB。
如果将Llama 4 Scout 109B模型(启动17B参数)搭配Q4 K M数据类型的上下文窗口设置为256,000字词,占用的显示内存容量将高达92GB。
 模型上下文协议(Model Context Protocol,以下简称MCP)能让大型语言模型与其他应用程序沟通,强化代理式AI的功能。
模型上下文协议(Model Context Protocol,以下简称MCP)能让大型语言模型与其他应用程序沟通,强化代理式AI的功能。
</p>
AMD提供通过Llama 4 Scout推导马克士威方程组的推理过程展示视频。
AMD提供通过MCP与应用程序协作的展示视频。
AMD表示MCP的正处于快速扩展的发展阶段,Meta、Google、Mistral等模型开发商也在训练AI模型的过程中增加调用应用程序与工具的“技能”,可以预见未来的模型将更能加善各类工具,强化大型语言模型的“智力”。








