
在Advancing AI 2025大会上,AMD董事长暨首席执行官苏姿丰表示,AMD在人工智能领域的发展步伐从未停歇,始终致力于设置产业新标准,为客户提供真正可部署且具备可扩展性的解决方案。
AMD Instinct MI350系列,赋能当代AI工作负载为满足现代AI基础设施的需求,AMD推出了AMD Instinct MI350系列GPU,包含MI350X和MI355X型号。这些GPU基于AMD CDNA 4架构,目的在赋能各行各业的创新者,帮助他们更快发展、更聪明地扩展,并创建未来。
MI350系列在AI运算能力上实现了4倍的提升,并在推理能力上取得35倍的飞跃。这为各行各业的变革性AI解决方案铺平了道路。在内存方面,MI350系列提供领先业界的288GB HBM3E内存容量,以及高达8TB/s的内存带宽,确保推理和训练都能获得卓越的传输量。
在部署弹性方面,Instinct MI350系列支持灵活的风冷和直接液冷配置,并针对无缝部署进行了优化。风冷机架最多可支持64个GPU,而直接水冷机架则可支持高达128个GPU,能够提供高达2.6 exaFLOPS的FP4/FP6性能。这使得在基于行业标准的基础架构中加快AI落地速度并降低成本成为可能。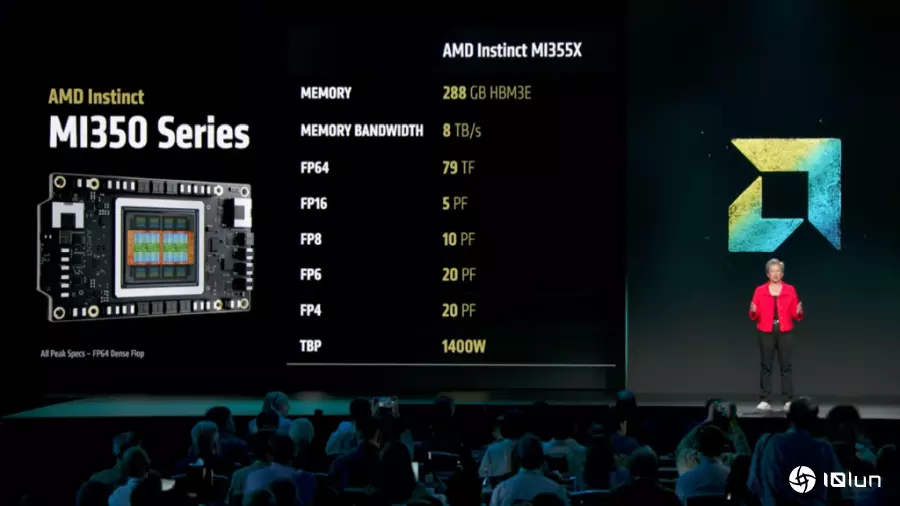
另外,MI350系列的生态系统发展势头强劲,随时可供部署。它将通过领先的云计算服务供应商广泛提供,包括主要的超大规模运算平台和新一代Neo Cloud,为客户提供灵活的云计算AI扩展选项。同时,戴尔 (Dell)、慧与科技 (HPE) 和美超微 (Supermicro) 等顶级OEM厂商正积极将MI350系列解决方案集成到其平台中,以提供强大的本地和混合AI基础架构。
ROCm 7用于AI加速的开放软件引擎苏姿丰强调,人工智能正以创纪录的速度发展,而AMD的ROCm愿景是通过一个开放、可扩展且以开发者为中心的平台,为每个人解锁创新。在过去一年中,ROCm迅速成熟,提供了领先的推理性能,扩展了训练能力,并深化了与开源社交媒体的集成。
ROCm目前已为全球一些最大的AI平台提供支持,从第一天起就支持LLaMA和DeepSeek等主流模型。在即将发布的ROCm 7版本中,实现了超过3.5倍的推理性能提升。凭借频繁的更新、FP4等高级数据类型以及FAv3等新算法,ROCm正在赋能下一代AI性能。同时,它也正在推动vLLM和SGLang等开源框架以比封闭式替代方案更快的速度发展。
随着AI应用从研究转向实际的企业部署,ROCm也随之不断发展。ROCm企业AI将全端MLOps平台推向前沿,通过用于微调、合规性、部署和集成的交钥匙工具,实现安全、可扩展的AI。目前,已有超过180万个Hugging Face模型开箱即用,显示ROCm不仅在迎头赶上,还在引领开放式AI革命。
开发者始终是AMD一切工作的核心。AMD致力于提供卓越的体验,通过更强大的开箱即用工具、即时CI仪表板、丰富的数据以及活跃的开发者社交媒体,让采用ROCm的构建变得前所未有的轻松。为了加速创新,AMD非常高兴地推出了AMD开发者云,让开发者能够即时、无障碍地访问ROCm和AMD GPU。无论是优化大型语言模型或扩展推理平台,ROCm 7都能提供开发者所需的工具,帮助他们快速从实验阶段转向生产阶段。
未来预期AMD Instinct MI400系列和“Helios”AI机架式服务器苏姿丰强调,AMD对创新的承诺不只于Instinct MI350系列,该公司已预览其下一代AMD Instinct MI400系列,预计将于2026年推出,代表着全新的性能水平。AMD Instinct MI400系列将代表性能的显著飞跃,为大规模训练和分布式推理提供全机架式解决方案。AMD Instinct MI400系列主要性能创新包括高达432GB的HBM4内存,19.6TB/s的显存带宽。FP4性能下达到40 PF,FP8性能下达到20 PF,高达300GB/s的横向扩展带宽。
而同样将于2026年推出的还有“Helios”AI机架式服务器架构,其全新设计目的在将AMD领先的芯片,AMD EPYC Venice CPU、Instinct MI400系列GPU和Pensando Vulcano AI NI,以及ROCm软件集成到一个完全集成的解决方案中。Helios被设计为一个统一的系统,支持紧密耦合的纵向扩展域,最多可容纳72个MI400系列GPU,纵向扩展带宽高达260TB/s,并支持Ultra Accelerator Link。
(首图来源:科技新报)








