
AMD在消费级AI性能说明会中,展示自家处理器产品在执行Llama 2与Mistral等大型语言模型的性能领先Intel Core Ultra最高达17%。
大型语言模型(Large Langue Model,以下简称LLM)是现在相当热门的生成式AI应用,用户可以直接与系统通过自然语言的文本沟通,询问并得到有参考价值的回达。其中以程序编译为主要应用领域的Llama Code,甚至可以在分析用户的需求描述之后,生成对应的程序代码。
虽然目前有许多云计算版本的LLM服务,用户可以直接通过浏览器进入操作界面,快速享受LLM的便利,但是这类服务大多需要收费,使用时也需要连接至网络。
AMD在官方博客推荐LM Studio软件组件,用户可以轻松将LLM安装至自己的计算机并在脱机状态下使用,这样的好处除了不需支付使用费,而且可以在没有网络的情况下使用之外,更重要的是所有数据都是在本机计算机处理,不需上传至云计算,所以不用担心数据外泄的风险,对于处理机密敏感数据或是生成公司使用的程序代码时格外重要。
 用户通过LM Studio软件组件就能在自己的计算机上脱机执行LLM。
用户通过LM Studio软件组件就能在自己的计算机上脱机执行LLM。
 脱机执行的好处包括确保隐私、不需支付使用费、不需联网。
脱机执行的好处包括确保隐私、不需支付使用费、不需联网。
AMD提供通过AI在Unity撰写弹跳球体程序代码的范例展示。
以AMD Ryzen 7840U处理器为例,它具有CPU(中央处理器)、GPU(绘图处理器)、NPU(神经处理器)等不同运算单元,CPU除了能够进行一般通用型运算之外,也通过AVX-512以及VNNI等指令集来强化AI运算的性能表现。
GPU的主要工作虽然是搭建3D图像,但是因为其架构的特性,也很适合用于加速AI运算,而NPU则是专为AI运算设计的加速运算单元,内置于部分Ryzen 7000与8000系列。活用这3种不同的运算单元,将可提升多种AI运算负载的性能表现。
根据AMD提供的数据,在使用搭载AMD Ryzen 7840U的HP Pavilion Plus以及搭载Intel Core Ultra 7 155H的Acer Swift SFG14-72T等笔记本时,在执行Llama 2与Mistral的性能表现最高可领先14%与17%,而在产生第1个Token(可以粗浅理解为词汇)的速度则最多快了79与41%。
需要注意的是,Ryzen 7840U的TDP仅为15W,大约仅为Core Ultra 7 155H 28W的一半,这代表的是在执行AI运算的过程中,Ryzen 7840U所消耗的电力更少,有助于提供更长的电池续航力,延伸AI运算的使用时间并避免电力耗尽。
 在AMD官方提供的范例中,以HP Pavilion Plus(右)与Acer Swift SFG14-72T(左)等笔记本作为测试平台。
在AMD官方提供的范例中,以HP Pavilion Plus(右)与Acer Swift SFG14-72T(左)等笔记本作为测试平台。
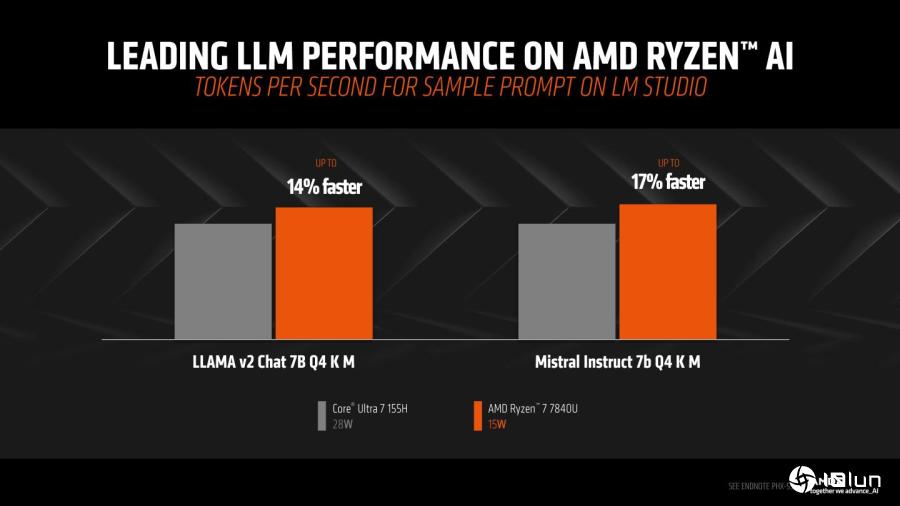 在Mistral Instruct 7B Q4 K M设置条件下,AMD Ryzen 7840U生成Token的速度领先IntelCore Ultra 7 155H达17%。
在Mistral Instruct 7B Q4 K M设置条件下,AMD Ryzen 7840U生成Token的速度领先IntelCore Ultra 7 155H达17%。
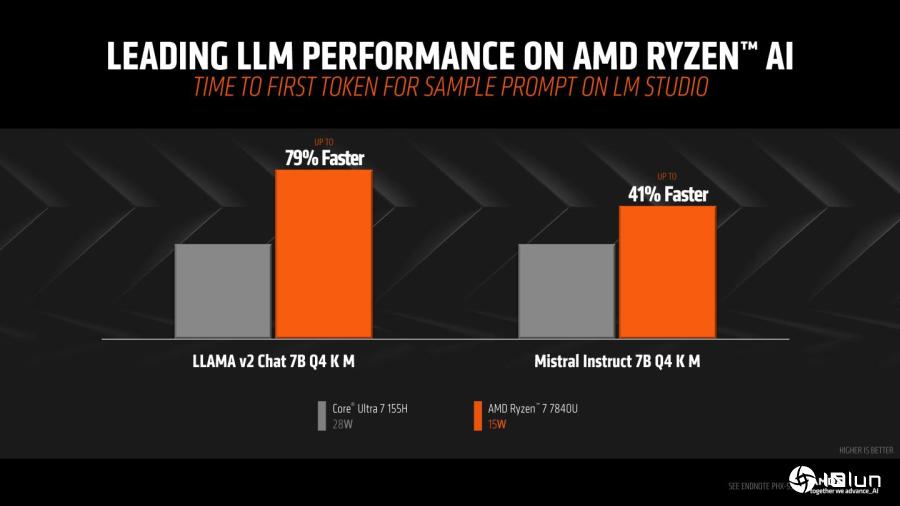 若比较从输入提示词到产生第1组Token的速度,Ryzen 7840U在Llama 2 Chat 7B Q4 K M设置条件下快了79%。
若比较从输入提示词到产生第1组Token的速度,Ryzen 7840U在Llama 2 Chat 7B Q4 K M设置条件下快了79%。
从实际视频中可以看到,右侧的AMD平台产生回应的速度明显比较流畅。
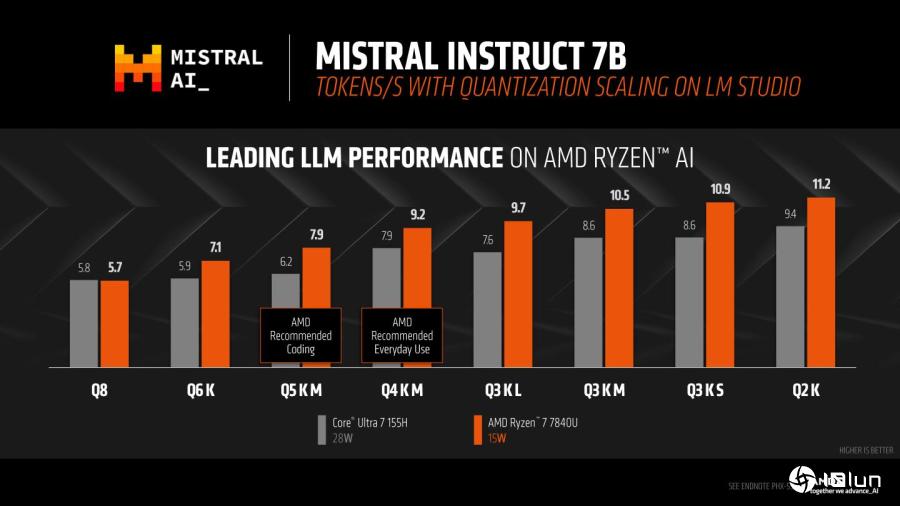 细看Mistral Instruct 7B在不同设置条件下的性能表现,AMD平台都优于Intel。(图表左侧代表回应越精准但速度越慢,AMD建议使用AI编写程序代码时设置为Q5 K M,一般应用设置为Q4 K M。)
细看Mistral Instruct 7B在不同设置条件下的性能表现,AMD平台都优于Intel。(图表左侧代表回应越精准但速度越慢,AMD建议使用AI编写程序代码时设置为Q5 K M,一般应用设置为Q4 K M。)
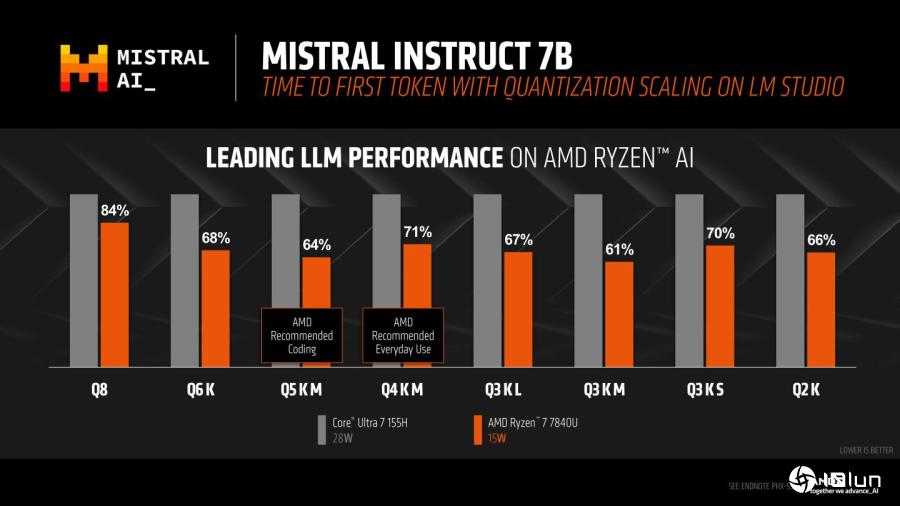 Mistral Instruct 7B在不同设置条件下产生首个Token的速度也都是AMD平台较快。
Mistral Instruct 7B在不同设置条件下产生首个Token的速度也都是AMD平台较快。
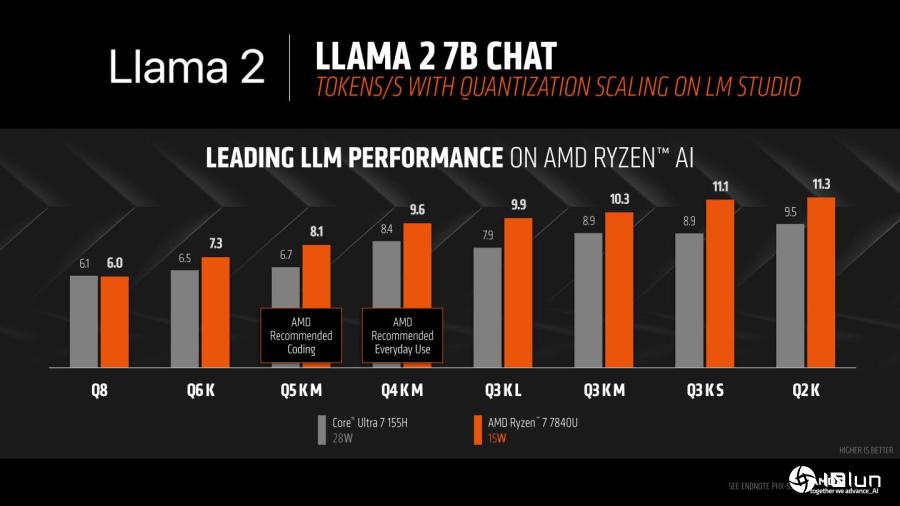 在Llama 2 Chat 7B的性能对照图。
在Llama 2 Chat 7B的性能对照图。
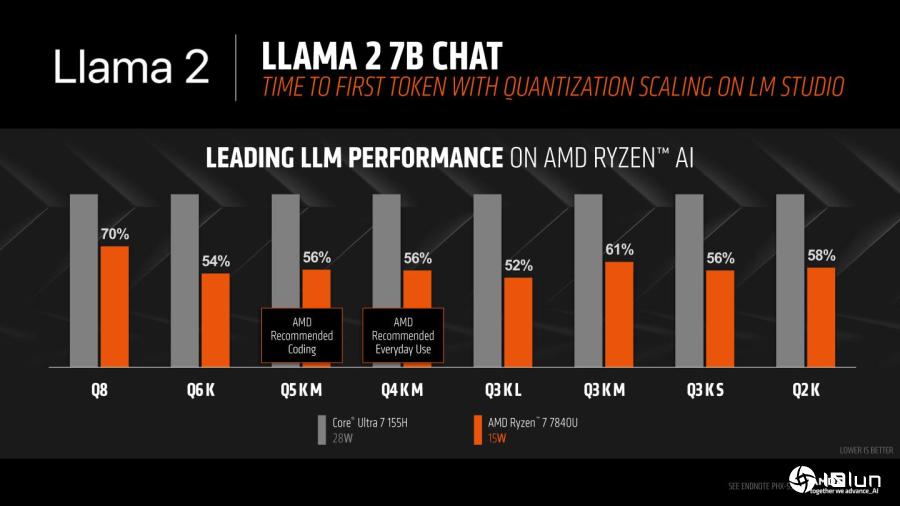 Llama 2 Chat 7B的首个Token速度对照图。
Llama 2 Chat 7B的首个Token速度对照图。
由于LM Studio软件组件对系统需求篇低,有兴趣的读者可以在自己的计算机安装并进行尝试。








